Premise
16 years ago proprietary flavors of Unix dominated enterprise computing and Microsoft’s server platform was just entering maturity. Then IBM made a commitment to the open source Linux operating system across all its platforms and the world shifted on its axis.
IBM is attempting to do the same thing for big data with the Spark platform. IBM isn’t saying it, but the competition this time around is Hadoop.
Hadoop entered its de facto second generation when all the Hadoop distributions standardized on the YARN cluster resource manager on top of HDFS. But the standard itself is somewhat tenuous. The unprecedented innovation around Hadoop has a price. Unlike Linux, Hadoop isn’t a product. It’s an ecosystem and every distro has a slightly different set of component products, each of which is on its own release cycle. And there is no single benevolent dictator like Linus Torvalds to hold it together. See figure 1.
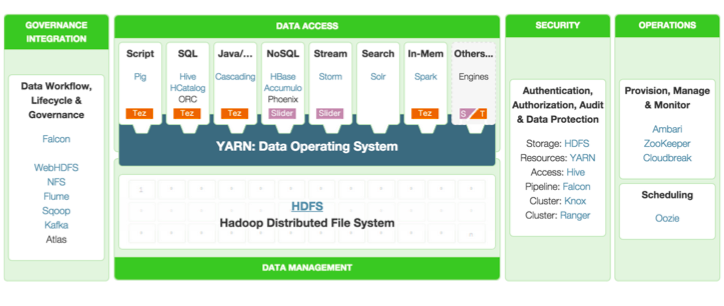
Figure 1: The individual products that comprise the current Hortonworks Hadoop distribution. Each has its own release cycle, permitting unprecedented innovation but at the cost of increased complexity.
What Spark lacks in maturity relative to Hadoop, it makes up for in simplicity. The core of its power is that it can handle all workloads with the same engine. The engine can work completely in-memory, if necessary, and handle real-time, interactive, and batch processing. It does this with several “personalities”, including machine learning, graph processing, SQL, and streaming. See the left diagram in figure 2. There’s another major benefit to having a unified engine. Performance improvements to support one personality add to all the other personalities.
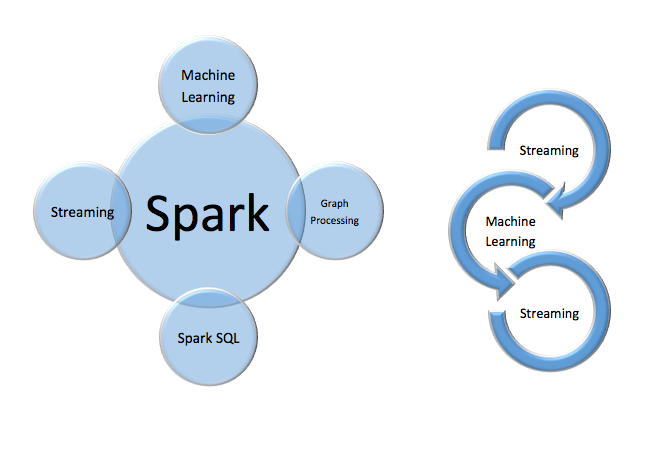
Figure 2: Spark is a single processing engine that has multiple “personalities”. This unification and deep integration make it possible to build applications where each step can involve capabilities from other parts of the product.
One way to understand the power of these tightly integrated personalities in one engine is Microsoft Excel. The spreadsheet can summarize its data as if it were a database; it can call on much of the statistical power of a dedicated modeling package; and it can visualize the data as well as if it were a standalone business intelligence tool, among other capabilities. The critical similarity is that a developer can build a “program” where each cell has a formula calling upon cells with potentially different personalities. See the right diagram in figure 2.
One application where Spark could use this integration in order to shine is in omni-channel marketing. In this scenario an enterprise might have a large data warehouse of historical information about its customers. It would use a batch machine learning job to create a profile model of each customer. When a customer interacts with any touch point in any channel of distribution, real-time observations about just what the customer is doing and what is happening around her streams into the Spark program. Spark uses that information to update the old model of the customer so that it can influence her interaction in real-time.
Hadoop would have more difficulty with this tightly-integrated, real-time scenario. Hadoop’s shared services are the HDFS file system and the YARN cluster resource manager. Neither is a shared processing engine like Spark. Instead, each component in a pipeline would typically perform its processing task, store the result in the file system, and then hand-off the next step to the next processing task.
Is this the end of Hadoop? Not likely. While the Hadoop end-to-end pipeline would typically have a hard time matching an equivalent Spark one, individual Hadoop processing tasks have one big advantage over Spark tasks. Hadoop tasks are optimized for just one function. So, for example, the Facebook-originated Presto SQL data warehouse that Teradata is commercializing is likely to have greater capacity and speed than anything built on Spark for the foreseeable future.
See figure 3.
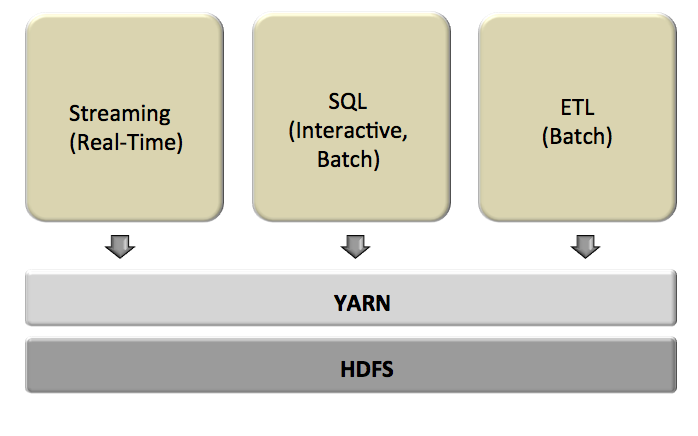
Figure 3: Hadoop processes data sequentially, one step at a time. An analytic pipeline would typically have slower performance than one with similar functionality in Spark.
Action Item
Hadoop is by no means going away. In fact, Spark may help entrench HDFS and YARN. But with IBM’s bestowing legitimacy, Spark may unify much of the processing layers that are today separate in Hadoop. Spark is no longer an academic project. All IT organizations, especially those that are struggling with the operation of Hadoop clusters, should consider piloting Spark. Data scientists, developers, and administrators need to vote on this before making unequivocal commitments to a specific Hadoop distro.


