Premise
Analytics in the age of Systems of Intelligence are very different from those in Systems of Record. They drive decisions that augment or automate humans in real-time rather than report on historical corporate performance.
A new crop of vendors has emerged to address the new requirements of the analytic data pipeline in Systems of Intelligence. Informatica, which dominated the last generation, has retooled and reemerged and finds itself predominantly facing emerging vendors with focused functionality. Informatica’s most important marketing challenge is to articulate the value of its integrated approach.
This research note will shine a light on some of the key requirements of the emerging tools. Now that Informatica Big Data release 10 has arrived, it’s time to reviews the market and some of the products. The next research note will present examples of some the focused approaches compared to the more integrated approaches such as Informatica.
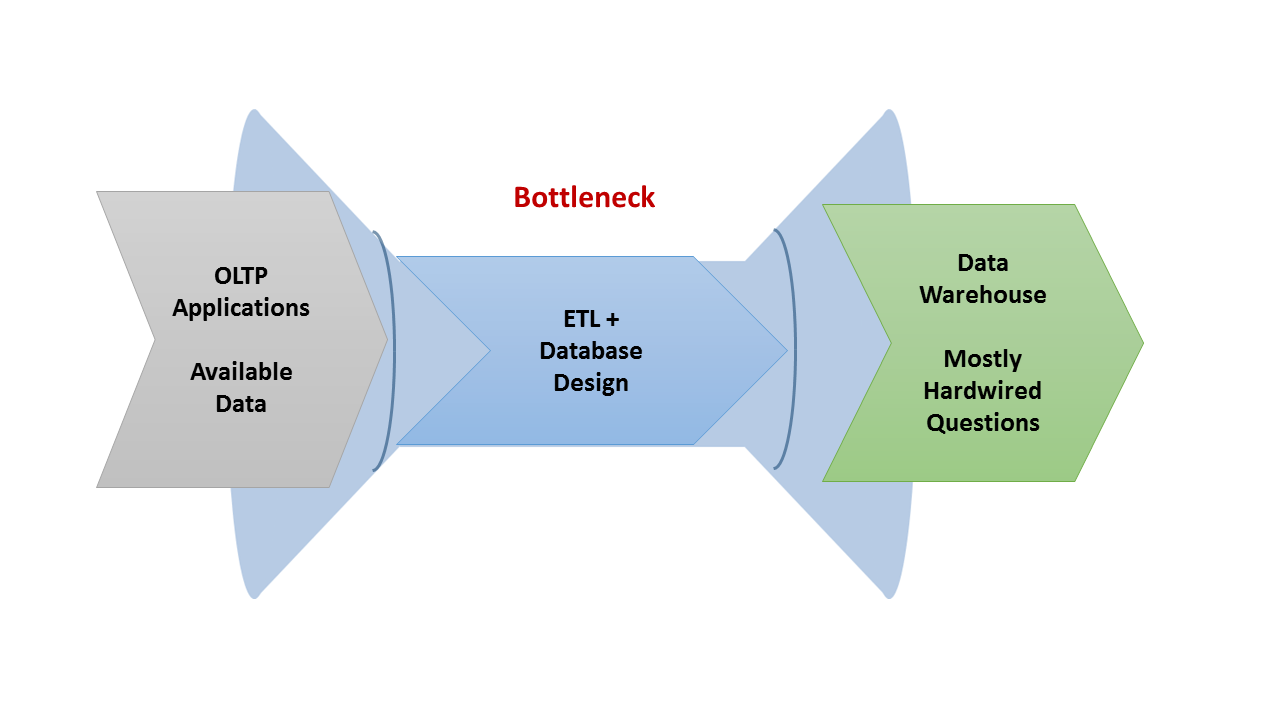
Traditional analytic data pipeline: from OLTP applications to Data Warehouse via ETL
The traditional data warehouse pipeline is very well-known but we’ll touch on key elements for the purpose of contrasting the emerging Hadoop-based version. The core of the traditional pipeline is that pretty much everything is known upfront. Working backwards, data architects know what data must be loaded into the warehouse to support the necessary queries. They know what intermediate transformations the ETL hub is required to support those queries. And they what data must be extracted from source applications to feed this pipeline.
Source: Wikibon 2015
The accepted terminology divided those three stages into Extract, Transform, and Load (ETL). That everything was known and baked into the pipeline made it very brittle. Changing requirements was a difficult process. On the other hand, the data warehouse was highly curated and easy to navigate.
New requirements for the age of Big Data
In the age of big data just about everything about the pipeline changes. The need for ETL technology grows not just in proportion to the volume of data, but it must encompass the explosion of variety of machine-generated data. And with the need for ever greater speed in executing analytic decisions, the pipeline must transition from batch to near real-time streaming. Unpacking this summary, there are several concrete changes in the ETL part of the pipeline.
Governance: cataloging data and tracking lineage
With the proliferation of sources and targets and the transformation steps in between, there is a greater need for a catalog that inventories the data and that tracks its lineage from end to end. Inventorying the data is critical for enabling successive sets of users to iteratively add structure to the Data Lake and make it more easily navigable for those who perform analytics downstream. Tracking the lineage of that data becomes ever more important because the proliferation of transformations and analytic steps makes trusting the end product ever more challenging.
Data Wrangling: unknown source data
The whole data pipeline has to transition from relational data that was designed to capture business transactions to machine data, typically in JSON format, that captures the events in application log files and the output of sensors in the IoT. Much greater emphasis has to go into tools that explore and make sense raw, uncurated data.
Security: getting beyond traditional perimeter security and permissions
Traditional security models feature a login and then permissions to access different slices of data. But with pervasive data and coming from and going to a range of new sources and destinations, whether new users or applications, a new security model is required. Rather than that explicitly designate permissions, policies become the new approach.
Integration and Runtime
With more unknowns in the data sources and the ultimate analytic targets, ETL developers need greater productivity in performing their transformations and enrichment. That means a highly productive drag and drop development environment. With the greater volume of data, the ETL runtime has to scale-out in order to meet performance windows. And with the need for ever faster performance of analytics, the ETL runtime must support near real-time streaming.
Building on leadership in a prior generation
Informatica defined the ETL market in the era of the data warehouse. As Data Lakes become the pervasive, next generation platform, the previous generation’s incumbent typically has the choice of leveraging one of the two sources of their existing advantage.
- They can either leverage on their existing technical foundation or their privileged access to customers. Recognizing that Data Lakes are different in so many ways from data warehouses, Informatica has built a new foundation technology to serve the new needs.
- And while there isn’t a 100% overlap in buyer roles, Informatica’s reputation still gives them privileged access to those who work with data in Data Lakes.
Action Item
IT practitioners should collect the requirements from each of the constituencies that are going to be involved in building the new analytic pipeline. If an integrated product such as Informatica or Pentaho doesn’t meet the requirements, they should evaluate just how much internal integration work they can support and whether the speed of the final pipeline can deliver on its performance goals. The more sophisticated enterprises with more specialized skills typically can support highly custom solutions.


