Premise
The days of performance enhancements coming from silicon technology only are over. Intel has successfully grown its x86 processor business by supplying 95% of the chips for PCs, and x86 in general accounted for over 80% of server shipments. Intel focused on silicon leadership by being at the forefront of chip fabrication.
However, the processor world is changing rapidly. ARM processors now account for 86% of devices as a whole, and are driving the latest fabrication methods. PC sales are declining by ~10%/year. Whereas the volume market for general purpose servers is still x86, the ability of the x86 to supply the performance end of the server market is under significant threat. The reason for this threat is the technology reality that silicon technology alone has reached the limit for performance improvements. Intel can continue to deliver cost-effective solutions for simple workloads. However, for more performant and higher value workloads, the only way forward is for software moving much closer to silicon, Software-in-Silicon. This is also true for sensor-based edge systems at the lower end or the server market. The software and hardware need to be designed together.
The key participants in Software-in-Silicon at the high-end of the server market are the IBM-led OpenPOWER foundation and SPARC processors from Oracle (M7) and Fujitsu. The key participants at the low-end and edge markets come from developers of systems based on ARM-based processor. The processor vendors are claiming that other Software-in-Silicon architectures will account for well over 20% of the server market by 2020. Wikibon believes that there is a strong probability that this will be the case.
Wikibon recommends that CIOs and senior executives responsible for IT should make platform decisions based on the best performance for the software being run, and should develop software-led RFP processes. The software required to the deliver enterprise digital transformation will increasingly by driven by integrated software/hardware architectures.
Microprocessor Fundamentals
The history of processors has been the result of advancements on multiple vectors;
- the number of transistors that can be place on a silicon chip (now measured in billions);
- the speed of processors (now measured in GHz);
- the number of processors cores that can work together to drive applications and solve problems.
Number of Transistors
The first point illustrated in Figure 1, which shows Moore’s law. This predicts that the number of transistors in a microprocessor will double every eighteen months. Figure 1 shows the growth from the Intel 8080 with 6,000 transistors in 1994 to the Intel Haswell processor with 5.5 billion transistors and the newly announced Oracle/Fujitsu SPARC processor with over 10 billion transistors. An amazing track record.
Processor Speed
The second issue, the speed of processors was more doubling every 2 years. From 1992 the clock speed went from 0.5GHz in 1992 to 3.0GHz in the Intel Pentium 4 in 2002, a rate of increase of just over 50% compound growth per year (CGR).
The physics of the amount of power required to drive additional power then kicked in with a vengeance. The 64-bit Pentium Xeon reached 3.6 GHz, and since then the maximum GHz in a commodity chip has been a maximum of about 4.0GHz, with the IBM mainframe chip an outlier at the top with 5.2 GHz.
Source: Wikibon update on work by Wgsimon (Own work) downloaded March 2016 from https://upload.wikimedia.org/wikipedia/commons/0/00/Transistor_Count_and_Moore%27s_Law_-_2011.svg
Number of Processor Cores
The latest Intel x86 processor is 22-core Xeon Xeon E5-2600 V4, with 7.2 Billion Transistors. The focus has been increasing the number of cores to a maximum of 22. However, the performance base is 1.8 GHz, with turbo-power taking it up to 2.6GHz.
For very simple applications where every user is independent (stateless applications), such as simple read-only web-based search applications, greater parallelism from increased cores per processor can reduce the cost of processing. However, for more performant workloads, there is a limit to the number of separate processors that can be applied to a software problem. That limit is Amdahl’s Law, based on the work by Gene Amdahl.
Amdahl’s Law Constrains Core Utilization
When there are software dependencies, Amdahl’s Law come into play. In all applications with any defined or implied state (and even in stateless applications) there are sections where a single process is required. Figure 2 gives a practical case case study of Amdahl’s Law. The percentage parallelism in this study is 95%. The speed-up with 95 parallel processors is 16.7 times. The maximum speedup with infinite processors is 20 times.
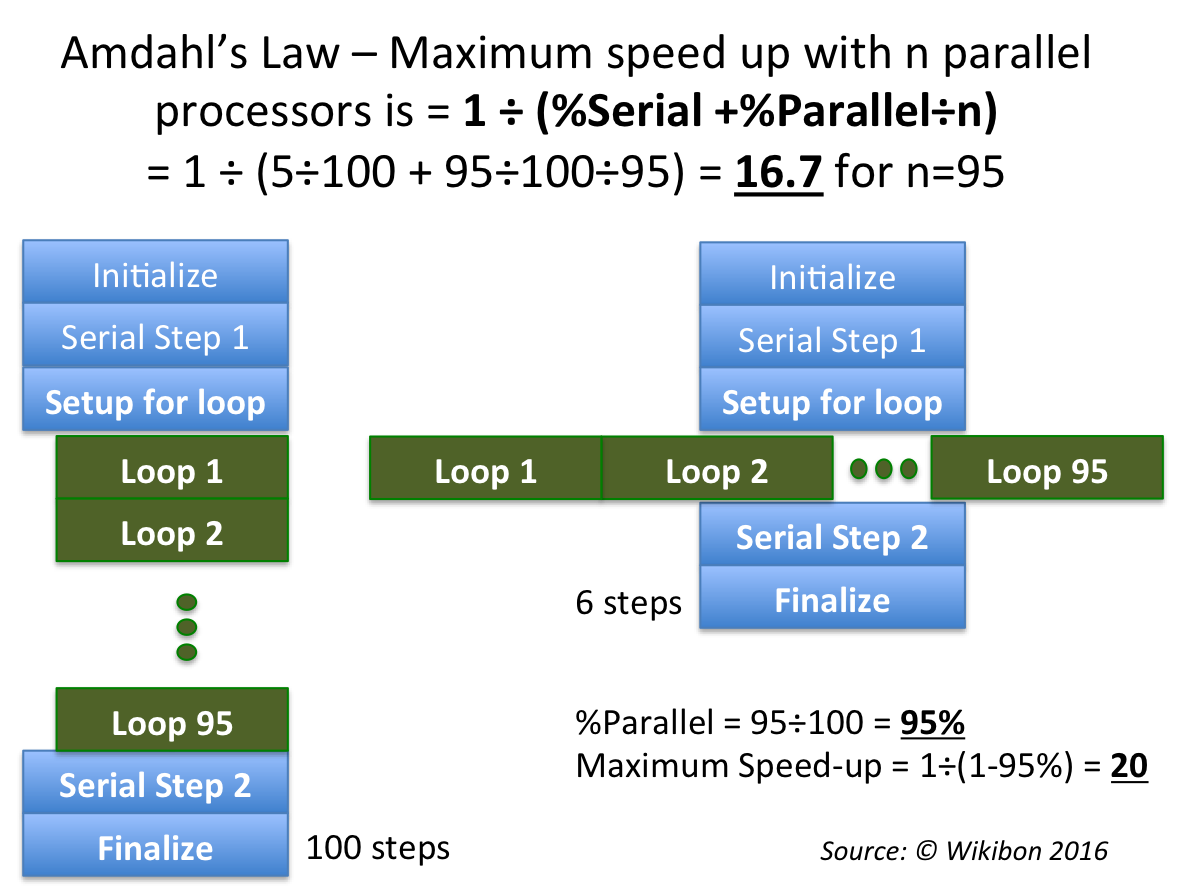
Source: © Wikibon 2016
Figure 3 below shows the impact of Amdahl’s Law on the speedup of performance-constrained applications. It is dependent on the percentage of the application that can be parallelized. If 95% can be run in parallel, the maximum speedup is 20 times. For 90%, the speedup is 10 times and takes 1,000 processors. Achieving such levels of parallelism is extremely difficult, even in pure scientific applications. For commercial applications, it is virtually impossible except for the very simplest state-free applications.
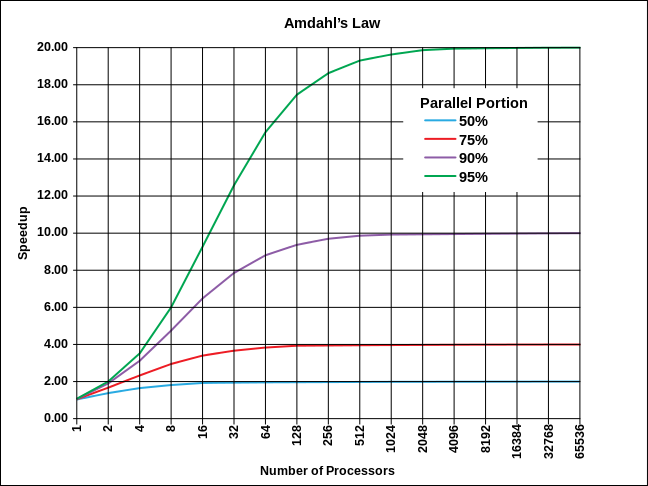
Source: Daniels220 at English Wikipedia, downloaded March 20 from https://en.wikipedia.org/wiki/Amdahl%27s_law#/media/File:AmdahlsLaw.svg
Amdahl’s law assumes constant resources. In practice, as more computing resources become available, more resources (e.g., cores) can be deployed to increase the work done in the parallelizable part of the work, and the time spent in the parallelizable part grows faster than the serial work. This is known Gustafson’s law, and gives a less pessimistic and more realistic assessment of the potential benefit of parallel systems. However, the bottom line is that serial components are the most significant performance constraint.
The conclusion from Figure 2 and Figure 3 and the discussion above is that for most applications, 16-32 cores is the maximum number of cores that can be driven by majority of enterprise performance-constrained applications. Smart ways have to be found to improve the elapsed time performance of the serial components of transaction. These components are often in the operating system, and middleware (especially database) components.
One area of speedup has been the use of flash for all the IO, which lowers IO latency and even more important lowers the IO variance. The software now becomes the next factor that must be reduced, and this can be reduced using PCIe and NVMe instead of the classic IO SCSI stack. The latest chips have much improved memory buses in the processors, which allow the intercommunication between the cores to be more efficient, and act more like an SMP processor. All of these speed-ups can and should apply to performance constrained applications.
When all these are applied, this still leaves the problem of the serial part of the code. Rewriting code is possible, but much of this code has already been optimized. The only solution left is to start to put some of this serial code in hardware, a Software-in-Silicon solution. This is especially important in database systems (especially in lock management), and in real-time big data systems. At the moment, most of the research for Software-in-Silicon is taking place outside of Intel, using ARM, OpenPower and SPARC processor complexes in particular.
The need for Software-in-Silicon
The solution to the silicon-only processor constraints is Software-in-Silicon, bring the silicon much closer to the software. New processor architectures are now available to design hardware solutions for particular software functions. Instead of designing the processor first, and the software afterwards, the processor and software are being designed together. The processor architectures use instruction extensions in silicon to improve specific functions, as well as Silicon-in-Software FPGAs (Field-Programmable Gate Arrays), GPUs and NICs that can be programmed by software developers to solve specific problems. Examples of this approach include:
- Apple‘s 9.7-inch & 12.9-inch iPad Pro integration of an ARM-based A9X two core processor with 51 GBytes/second bandwidth and 12 graphic cores together with the Apple iOS software to achieve equivalent end-user perceived performance as a high-end Intel laptop processor. Apple’s overall processor hardware cost is much lower than equivalent Intel processor hardware.
- The creation of the OpenPOWER Foundation, with Google, IBM, Mellanox, Nvidia and Tyan as founding members. The CAPI feature of POWER 8 allows the efficient connection of Software-in-Silicon FPGAs, GPUs, and NICs. IBM’s POWER 8 processor combined with IBM DB2 is focused on improving big data and analytic processing.
- The announcement of the Oracle SPARC M7 processor with performance and security extensions in Software-in-Silicon to improve Solaris and Oracle Database Processing, with chip volumes coming from the joint development with Fujitsu.
- The RISC-V Foundation (pronounced risk five) is an open source instruction set architecture, with small, fast, and low-power implementations in mind.
Intel has responded by acquiring Altera, an FPGA company, which was finalized in January 2016. To date, all Intel’s architecture extensions have been developed for x86 use only, such as the Intel Enhanced Privacy ID (EPID) technology. Intel will need to move to much closer ties with large software companies, and create open source extensions. Wikibon would expect a three to four year timescale before Altera FPGAs are fully integrated with the Intel x86 roadmap. One key strategic concern to very large processor users and large software companies is the increasing prices of Intel x86 architecture microprocessors, as a result of a current near-monopoly and bundling. These same users do not want to pay for features they do not use. These additional factors are also driving strong acceptance of new non-Intel architectures discussed above.
Conclusions
The x86 microprocessor has reached an architectural limit for performance-constrained applications. This limit is as the result of a processor cycle-time freeze, and a limit to the number of processor cores that can be applied to an application. Intel can no longer expect economies of scale to drive market share in x86 processors for this high-performance segment of the processor marketplace, as well as the sensor-heavy edge systems.
For performance-constrained applications, future advances will come from designing the microprocessor and software together, and Silicon-in-Software solutions. There are multiple large niches that have opened up to new processor/software approaches, including mobile, IoT servers, specialized servers for the cloud, telecommunications servers and large system servers for large database and big data applications.
For the next few years, winners in this space are likely to come from companies like Apple, Amazon, Fujitsu, Google, Hitachi, IBM, Microsoft and Oracle. After the integration of Intel and Altera, Intel will also compete after it has integrated the acquisition of Altera into its roadmap. The key challenge will be the rate of experimentation and software component development will be high, and will challenge Intel’s traditional proprietary architecture development process.
When the cycle-time improvement stopped in about 2006, the number of applications that were performance-constrained was very small. In the ten years since, the focus has been on implementing parallel software solutions, and this approach has now reached its own limit. Wikibon expects that the percentage of applications that are performance constrained will now rise significantly year over year. Wikibon’s preliminary estimation is that over 20% of processor spend will be for performance-constrained applications by the end of the decade. Wikibon believes that the only effective way to address this market is to include Software-in-Silicon in the processor architecture.
New winners in this performance-constrained space are likely to come from companies like Apple, Amazon, Fujitsu, Google, Hitachi, IBM, Microsoft, and Oracle. Intel will continue to provide low-cost solutions for applications which are not performance constrained. The benefits of using these non-Intel architectures for performance-constrained workloads will be better performance, better functionality, and improved end-user productivity.
The winners is the cloud space will be Software-as-a-Service (SaaS) cloud service providers, who will find many more opportunities to improve their software by marrying it to a range of silicon-based solutions.
Action Item
Wikibon recommends that CIOs and senior executives responsible for IT should make platform decisions based on the best performance for the software being run, and should develop software-led RFP processes. The software required to the deliver enterprise digital transformation will increasingly by driven by integrated software/hardware architectures.
For applications with high business value and high performance constraints, doers should evaluate new non-Intel architectures which combine traditional microprocessor and Software-in-Silicon functionality. This is particularly important in:
- the development of large database systems;
- the deployment of Systems of Intelligence, which combine big data analytics with systems of record to achieve real-time automation of business functions.
The business benefit of improved performance, functionality and end-user productivity from Software-in-Silicon will totally outweigh any additional processor costs in either of these scenarios.



{kind=link}