Premise
Agile is a methodology under which self-organizing, cross-functional teams sprint towards results in fast, iterative, incremental, and adaptive steps. Agile methodologies are taking root in data science, though there are issues that may impede the success of these efforts. One of the greatest risks with agile in data science is that it could compromise the work’s reproducibility, hence credibility and downstream usability.
Analysis
Agility is fundamental to business’ ability to successfully build systems in a world where it’s difficult to predict the future. Data science and new big data business capabilities (e.g., machine learning, AI) are becoming essential to optimally anticipate the future. How will these two crucial technologies come together?
To some extent, Agile methodologies are already being implemented in data science teams, but not universally or consistently. During a recent Wikibon research Crowdchat, we surveyed nearly 100 experts in the data science and agile fields about the adoption of Agile practices in data science teams. This slice of our Wikibon community reported believing that 25-50% of data science teams are employing Agile methodologies (see Figure 1). We believe this figure to be accurate. For example, Agile is consistent with the time-honored CRISP-DM methodology of iterative modeling, deployment, evaluation, and refinement in statistically-driven knowledge discovery. Moreover, a quick assessment of expert comments regarding the definition of Agile in the context of data science yields an important and broad consistency (see Figure 2).
To ensure that Agile methodologies contribute to your development team’s productivity on data science initiatives, you should heed these high-level guidelines:
- Bring Agile into data science team development processes. Agile methodologies can boost the productivity of complex collaborations among data science teams as well as between data scientists and other developers.
- Deploy Agile-enabling data science development tools and platforms. Considering that data science is increasingly a team-oriented discipline, it’s essential that statistical modelers, data engineers, business analysts, visualization designers, programmers, and others in the development team be able to pool their efforts within open, collaborative environments.
- Ensure that Agile processes don’t compromise data-science reproducibility. In data science development teams, reproducibility can be the greatest agility enabler of all. If statistical modelers ensure that their work meets consistent standards of transparency, auditability, and accessibility, they thereby make it easier for others to review, cite, and reuse it in other contexts.
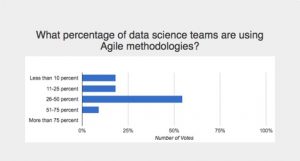
Figure 1: Agile Methods Are Diffusing Into Data Science Teams
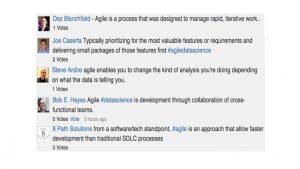
Figure 2: The Wikibon Community Agrees On The Definition of Agile in Data Science
Bring Agile Into Data Science Team Development Processes
Essentially, data science is an iterative process of searching for statistical insights. In the process of unlocking those insights, data science professionals may build, test, and discard one model after another until they find the one that fits the data best and identifies the specific correlations and other patterns of interest. Over the course of a specific data science project, data scientists may explore diverse data sets, evolve their approach for ingesting and sampling, and adjust the specific mix of features, predictors, and algorithms from which their models are built.
Data science is not amenable to classic top-down “waterfall” development methodologies, but, in the hands of professionals, it’s not an exercise in adhocracy either. In this as in other development disciplines, Agile methodologies can boost the productivity of complex collaborations among data science teams as well as between data scientists and other developers. It can do this while enabling rapid shifts in development priorities to meet changing requirements.
Agile breaks down to the core principles outline in Table 1, with specific emphasis on how one might apply these Agile practices to a typical data science development initiative: building, testing, deploying, and refining the analytic algorithms that optimize an enterprise’s digital-marketing applications. An overview of the principles is presented in Figure 1.
| PRINCIPLE | DEFINITION | HYPOTHETICAL SCENARIO |
| Start from the “minimum viable product” | The “minimum viable product” from a data science initiative is whatever deliverable adequately addresses some narrowly scoped business requirement using a minimal set of resources and tasks. | In a digital marketing scenario, this minimal deliverable might address some narrow requirement such as predicting a single scenario (e.g, whether one class of customers might accept one specific offer under tightly constrained circumstances). The application might be built from a single data source (e.g., relational customer database), incorporate just a few predictive variables into their feature set (e.g., customer gender and income), use just one well-understood statistical algorithm (e.g, linear regression), and few lines of programming code and other deterministic business rules (e.g., Python scripting in Linux). predictive model that’s more accurate than random guessing.” On the recent Crowdchat, one participant defined data-science MVP thus “MVP can simply be a predictive model that’s more accurate than random guessing.” |
| Build deliverables modularly from the minimum viable product | The “minimum viable product” from a data-science development exercise might serve as the modular foundation for a more complex application that addresses other requirements. | Using the example above, the core predictive app might be extended by other developers to address other scenarios (e.g, whether that same class of customers might accept other offers under different circumstances), leveraging other data sources (e.g., customer clickstreams from mobile commerce apps), more predictive variables (e.g., location, time of day, education level), and other algorithms (e.g, logistic regression for more fine-grained customer segmentation). Other code modules might be added as the application is elaborated to evolve beyond simple prediction toward classification and automated responses. |
| Evolve deliverables Incrementally | As each data-science application module gets developed, tested, and deployed–starting from the initial “minimum viable product”—it becomes part of the platform upon which future modules are incrementally built. | Staying with the example above, the incremental customer predictive-response application modules might figure into a target-marketing application that uses predictive analytics and business rules to send tailored offers to specific customer segments based on both historical and current data. As each incremental module is built out, it would draw from the core data, algorithms, features, code, and rules used in previous modules, but may also incrementally evolve these artifacts to address the special requirements of each subsequent module. |
| Use iterative steps at each phase to refine deliverables | In the process of developing each incremental module of a data science initiative, agile methodologies call for regular—perhaps daily or weekly—checkpoints in which developers come together to discuss changing requirements and review progress of each iteration of the proposed solution. | In the example above, these regular checkpoint meetings would involve face-to-face discussion (where feasible) to provide feedback on project status, identify suitable data sources, assess data-engineering requirements, review feature sets, discuss algorithms, critique coding, evaluate performance, and grapple with myriad other issues that surround each iteration of whatever predictive-analytics module they’re developing. Depending on the turnaround requirements of the project, these iterative “sprints” may be short or long in duration, and may catalyze fast results or risk compromising the more careful drawn-out planning needed on some complex projects. One of the Crowdchat participants stated that “for short term investigations #agiledatascience is useful and a good fit given the short timeline” but that “Long term projects tend to have more extensive requirements, deadlines, and milestones – In my experience, agile isn’t well suited to handle meeting all of these expectations.” |
| Adapt methodologies to changing project results and circumstances | Throughout the development lifecycle of any data science project, the team will flexibly adapt its structure, membership, dependencies, workflows, tasking, and technical approach to changing circumstances. | In the example above, a data-science development team may at various checkpoints realize that the data sources, sampling techniques, feature engineering, statistical algorithms, runtime environments, programming languages, and other aspects of their initial plan have proven counterproductive. The realization that a modification is necessary will usually come from varying blends of user direct feedback, comments from various development team members, and/or from the success (or lack thereof) of each version of a model to achieve intended learning outcomes. As data-science team members collaboratively work through these issues, they may, with each new Agile “sprint,” adapt by trying different customer data sources, building models around different regression and classification algorithms, bringing in different digital-marketing experts to refine the feature model, executing the models in a public vs. a private cloud, and so on. Throughout the process, the adaptive data science team will report milestones toward successful delivery, and cannot commit to specific interim task completions, as these cannot be predicted with certainty in the self-organizing, trial-and-error nature of a project with many unforeseeable variables. |
| Colocate team members to keep collaborations focused in real time | Under the agile approach, most of the teams’ participants and interactions take place in common physical location, or, as a second-best alternative, in a physical hub which some participants access remotely through regular video, audio, and other conferencing, collaboration, and other resource-sharing tools. The “minimal viable team” must always be co-located. | In the example above, agility requires that the core developers of the predictive marketing application–in other words, data engineer, statistical modeler, marketing specialist, data app coder—engage, at the very least, in weekly in-person checkpoint conversations. They may, however, engage other, remote personnel at various points in the data-science development pipeline. One example of the latter might be the administrators of the Hadoop-based data lake and the Kafka-based data streaming infrastructure upon which their project depends. |
Table 1. Applying Agile Principles to the Data Science Development Process

Figure 3. Agile Data Science Principles
Deploy Agile-Enabling Data Science Development Tools And Platforms
Development teams require common access to a comprehensive work environment in order to be as productive as possible using Agile methodologies.
For data science professionals within Agile development teams, productivity can be difficult to sustain if their modeling tools, algorithm libraries, and data platforms are disparate, fragmented, and siloed. Though statistical modelers, data engineers, business analysts, visualization designers, and other data science professionals have distinct roles in the development of data-science deliverables, they require a common hub for resource sharing, version control, and other core tasks essential to their incremental, iterative, and adaptive collaborations on common projects.
To support productive collaborations within Agile development environments, data science professionals require access to a common working environment with core features outlined in Table 2.
| FEATURE | DESCRIPTION |
| Rapid deployment | The environment should be deployable and useful to developers in less than an hour, and decommissioned just as easily, at no risk and with no infrastructure investment required. |
| Unified toolset | The environment should support unified access into data, algorithm libraries, code modules and other assets on existing platforms, into runtime engines and pipeline processes that be executed those platforms, and into facilities to move data and workloads between platforms. |
| Elastic scalability | The environment should facilitate flexible scale-up and scale-out from a small data-science platform as needs change, with the ability to elastically add, remove, and redistribute storage, processing, memory, bandwidth, and other resources on demand. |
| Comprehensive data lake | The environment should allow rapid inclusion of a growing variety of data types from diverse sources into a comprehensive data lake available for all data-science pipeline processes. |
| Self-service data discovery and acquisition. | The environment should enable self-service discovery and acquisition of data from diverse database, big data clusters, cloud data services and other data sources. |
| Flexible modeling, programming, and prototyping | The environment should enable modeling, programming, and prototyping of data applications in Apache Spark, R, Python and other languages for execution within in-memory, streaming and other low-latency runtime environments |
| Composable application and service workbench | The environment should streamline development of data-driven applications and microservices using a reusable, composable library of algorithms and models for statistical exploration; data mining; predictive analytics; machine learning; natural-language processing; and other functions. |
| Pipeline automation | The environment should automate end-to-end machine-learning processing across myriad pipeline steps—data input through model training and deployment—and diverse tools and platforms through support for standard application programming interfaces |
| Continuous benchmarking and iterative refinement | The environment should support continuous benchmarking of the results of data-science projects to enable iterative refinement and reproducibility of model and algorithm performance. |
| Lifecycle policy-based governance | The environment should enforce policy-based governance, security, tracking, auditing, and archiving of data, algorithms, models, metadata and other assets throughout their lifecycles. |
Table 2: Deploying an Agile-Enabling Team Data Science Collaboration Environment
Ensure That Agile Processes Don’t Compromise Data-Science Reproducibility, Transparency, and Accountability
Agile methodologies intensify developers’ natural inclination to skimp on documentation in the interest of speed. Considering that methodological improvisation is the heart of this approach, it’s not surprising that teams that follow Agile principles may neglect to record every step they took to achieve desired outcomes.
Reproducibility, transparency, and accountability depend on knowing the sequence of steps that produced a specific data-driven model, process, or decision. That, in turn, depends on having a trustworthy audit trail of the specific processes used by data science professionals to develop their machine learning, deep learning, predictive analytics, and other deliverables. It also depends on maintaining a rich repository of associated metadata and a log of precisely how particular data, models, metadata, code, and other artifacts executed in the context of a particular process or decision.
None of that is possible if the data scientists who built a machine learning, predictive analytics, or other model failed to document their procedures in precise detail. In those scenarios, where data scientists are in an Agile scramble to rapidly show results, neither they nor anybody else can be confident that what they found can be reproduced at a later date by themselves or anyone else.
To ensure that reproducibility isn’t undermined by Agile methods, data science teams should perform all their work on shared platforms that automate the following functions and maintain associated metadata and log information:
• Logging of every step in the process of acquiring, manipulating, modeling, and deploying data-driven analytics;
• Versioning of all data, models, and other artifacts at all stages in the development pipeline;
• Retention of archival copies of all data sets, plots, scripts, tools, random seeds, and other artifacts used in every iteration of the modeling process;
• Generation of detailed narratives that spell out how each step contributed to analytical results achieved in every iteration; and
• Accessibility and introspection at the project level by independent parties of every script, run, and result.
One of the Crowdchat participants said that Agile need not be inconsistent with upfront planning and in-project documentation, noting that “if you’re doing it right, Agile makes use of foundational aspects like User Stories to capture as much as you can up front in the for of a Documented Requirement you can then post launch use to “document” the thing” Another participant resorts to more of a post-hoc style of Agile documentation, stating “when I need to work fast, I just dump everything into one file/folder and create documentation for the parts that end up being used.”
In data science development teams, reproducibility can be the greatest agility enabler of all. If statistical modelers ensure that their work meets consistent standards of transparency, auditability, and accessibility, they thereby make it easier for others to review, cite, and reuse it in other contexts.
For all these reasons, data scientists should always ensure that agile methods leave a sufficient audit trail for independent verification, even if their peers (or compliance specialists) never choose to take them up on that challenge.
Action Item
To ensure that agile methodologies contribute to the productivity of your data-science development team, you should bring Agile into data science team development processes, deploy Agile-enabling data science development tools and platforms, and ensure that Agile processes don’t compromise data-science reproducibility. However, relying on data-science development platforms to ensure reproducibility is not enough. You must instill a steadfast commitment to reproducibility into the culture and training of all data-science professionals. That’s doubly important in by-the-book Agile culture where many interactions, reviews, collaborations, and checkpoints may be offline in face-to-face co-located teams.


