Premise
A new architecture and foundational big data capabilities are required to integrate big data applications with distributed operational, engagement, and IoT applications. Big data pros must master three new core big data application capabilities and understand how to architecturally weave them into deployment patterns.
Having spent several years developing the skills and processes to build and operate data lakes, the predominant big data infrastructure, big data groups are being told to integrate big data resources with applications that are increasingly distributed, including systems of record. This presents a unique challenge: How to deploy analytic pipelines across highly distributed, hybrid cloud data sources which can be on-premise, in multiple clouds, and stationed in multiple tiers on the edge. Many criteria drive choices for distributing big data pipeline and other resources in hybrid cloud settings
A few concepts are crucial to making sense of hybrid cloud architectures for big data. First is the collection of capabilities that will serve as the base for distributed big data systems (see figure 1). Second, big data pros must understand how to successfully weave these capabilities into operational patterns featuring common tooling, tasks, and other characteristics. Third, the architectural criteria that will determine deployment decisions, including latency for accessing and analyzing the data, regulations such as the EU’s GPDR, IP criticality of the data, cost, resource availability, and HA and DR concerns. Of course, the entire framework is predicated on understanding the base capabilities, which are:
- Microservices & streaming employ modern continuous processing approaches. These elements complement but don’t replace traditional request/response and batch processing approaches.
- Today’s distributed file systems and DBMSs manage traditional shared state. However, these conventional elements have been updated to offer greater flexibility to developers and administrators via options such as tunable consistency.
- Machine learning model building and/or execution can work in any combination of locations. Data to feed model building and/or execution can work with IoT edge devices; mobile and Web apps; systems of record; and rich, contextual, and historical data. Predictions and prescriptions will typically be near the decisions because of latency. The most challenging issue for now, however, is orchestrating the machine learning pipeline, which is typically distinct from the rest of the big data pipeline.
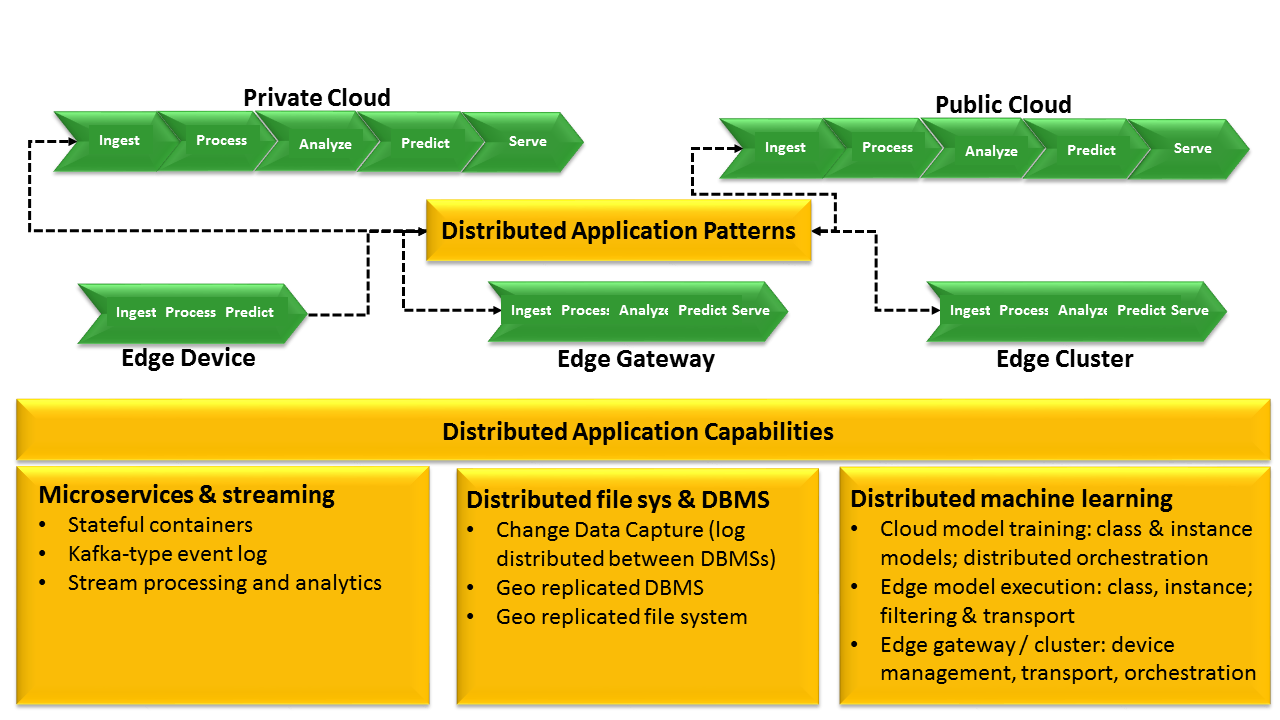
Microservices and Streaming Employ Modern Continuous Processing Approaches.
Rather than run periodic batch processes which operate on data accumulated since the last period, streams enable microservices to operate continuously, a crucial feature of emerging big data architectures. Microservices that communicate via stream processing typically deliver the most up-to-date data and analytics to consuming services and applications wherever they may be running. Microservices that communicate via streams lend themselves most naturally to distribution across on-prem, public clouds, and the edge because they don’t need to share their state synchronously. Rather, the streams by which they communicate assume asynchrony, a property that makes them ideally tolerant of geographic distribution. Emerging IoT applications, where data continuously originates at the edge, work particularly well with this capability. Kafka has done more to liberate and distribute this data than any previous type of data or application integration technology. And container technologies such as Kubernetes simplify the orchestration and distribution of microservices.
Deconstructing monolithic pipelines from using traditional, centralized databases for shared state requires microservice developers to take responsibility for all the challenges of managing their own data as well as how that data is published for others to consume. Traditional, shared databases made it simple to keep data consistent between application services or components. Microservices that manage their own data, however, have to maintain that consistency internally. Internalizing that database function that was formerly shared is typically more challenging than deconstructing monoliths into microservices. In the past, when developers needed to change the state shared between different services, they could “outsource” the transaction and let the database manage it. When each microservice manages its own state changes, if there is any need to coordinate state changes between microservices, one microservice should “own” the transaction and coordinate to ensure any related microservices implement their portion.
Modern Distributed File Systems and DBMSs Offer Options For Managing State That Needs To Be Shared.
Modern containerized microservices can use distributed databases and file systems to share state between each other rather than managing it internally to the containerized microservice. A shared state approach is easier for developers trained in conventional request/response and batch processing capabilities. And DBMSs and file systems can also ingest and share streaming data, typically with greater latency than stream processing, however. Using a DBMS or file system to share state means microservices can be stateless, which makes it much easier to orchestrate their deployment and operation via containers.
Unless you can use databases that can maintain transactional consistency across geographies, however, microservices can get bottlenecked trying to communicate between on-prem and the cloud. Communication with edge clusters would be even more challenging, given their more limited connectivity. Two exceptions to this rule exist. Google’s Spanner and Microsoft’s Cosmos DB can support transactional consistency across geographies by virtue of their deep integration with their global network infrastructure.
Machine Learning Model Building And/Or Execution Can Work In Any Combination of Locations.
Models have to be able to execute as well as get trained anywhere. Traditional data lakes have the richest repositories of contextual and historical data. Model building and training has typically taken place on-prem, where data lakes originated. But with IoT applications, data is increasingly originating at the edge. Not only must models execute there, but some amount of local training will have to take place to compensate for models that drift over time.
By far the biggest challenge is having a consistent model building and execution platform across locations, especially as models get closer to the resource-constrained edge. For now, distributed orchestration of model building and execution is more of a science project. Customers will typically have to build and train their models in one environment, such as a Spark cluster on-prem or in the cloud. Once trained, customers will have to convert the model to run on another platform, whether in a system or record or in a resource-constrained runtime platform on the edge.
Action item
The prescription for moving forward with a hybrid cloud architecture for big data is straightforward. Make an inventory of the location of your data assets. Calculate the SLA on the latency of the necessary analytics. Determine the constraints on the data distribution, such as data gravity or regulations. Then choose the hybrid cloud architecture that best serves these constraints.


