Premise
The premise of this research is that Heterogeneous Compute (HC) is deployed today in consumer mobile devices and can increase the performance of Matrix Workloads by a factor of 50 compared with traditional architectures. Also, this improves price-performance and power consumption by a factor of over 150. Enterprise HC is likely to use the same technologies as consumer HC. As a result, the Heterogeneous Compute improvements will dramatically increase the value of real-time Matrix Workloads, and especially the subset of AI inference workloads.
The more strategic premise is that while Heterogeneous Compute can reduce the cost of processing the data by a factor of fifty (50), the cost of storing and moving that data will be 50 times higher. If Matrix Workloads use traditional datacenter processes, the cost of the non-processor components will dominate. However, by using a Data-led Operational Architecture (DLOA), the storage and networking costs can be brought in line with the compute costs. The result of these two fundamental architectural changes is to allow real-time Matrix Workloads to process two orders of magnitude more data with the same cost envelope as traditional enterprise computing. Heterogeneous Compute running Matrix Workloads are vital technologies for data-led enterprises.
These premises are aggressive. This research to defend them is technical and includes all the technical facts, calculations, and assumptions. If other researchers find a mistake, omission, or lousy math, we will, of course, update our research. To help the less technical readers, we have included a “Bottom Line Summary” at the end of each major section to help understand the argument flow.
Executive Summary
Heterogeneous Compute Outperforms Traditional x86 for Matrix Workloads
Apple and Google adopted neural network technology first for consumer applications. In 2017, Apple shipped an early Heterogeneous Compute architecture in the iPhone X with integrated GPUs, processors, and a Neural Network Unit (NPU). This smartphone allows mobile users to take better pictures with software rather than hardware and improved privacy with facial recognition technology. Google ships a standalone NPU in its Pixel smartphones to enhance photography and audio functions, and also offers a heavy-duty cloud water-cooled TPU (Tensor Processing Unit) service aimed at Machine Learning (ML) development.
Wikibon defines the term Heterogeneous Compute architecture as a combination of CPUs, accelerators, NPUs, ASICs, a GPU, and FPGAs. These directly interconnect with each other at very low-latency and high bandwidth, much faster than DRAM can operate. We will expand these terms and their importance in the section “Defining Heterogeneous Compute Architecture” below.
In this study, the representative Heterogeneous Compute system is the Arm-based Apple iPhone 11. The traditional architecture is the latest x86 PC system based on the latest Intel i7-1065G7 technology. Figure 1 below shows a summary of the conclusions of the performance and price-performance parts of this research.
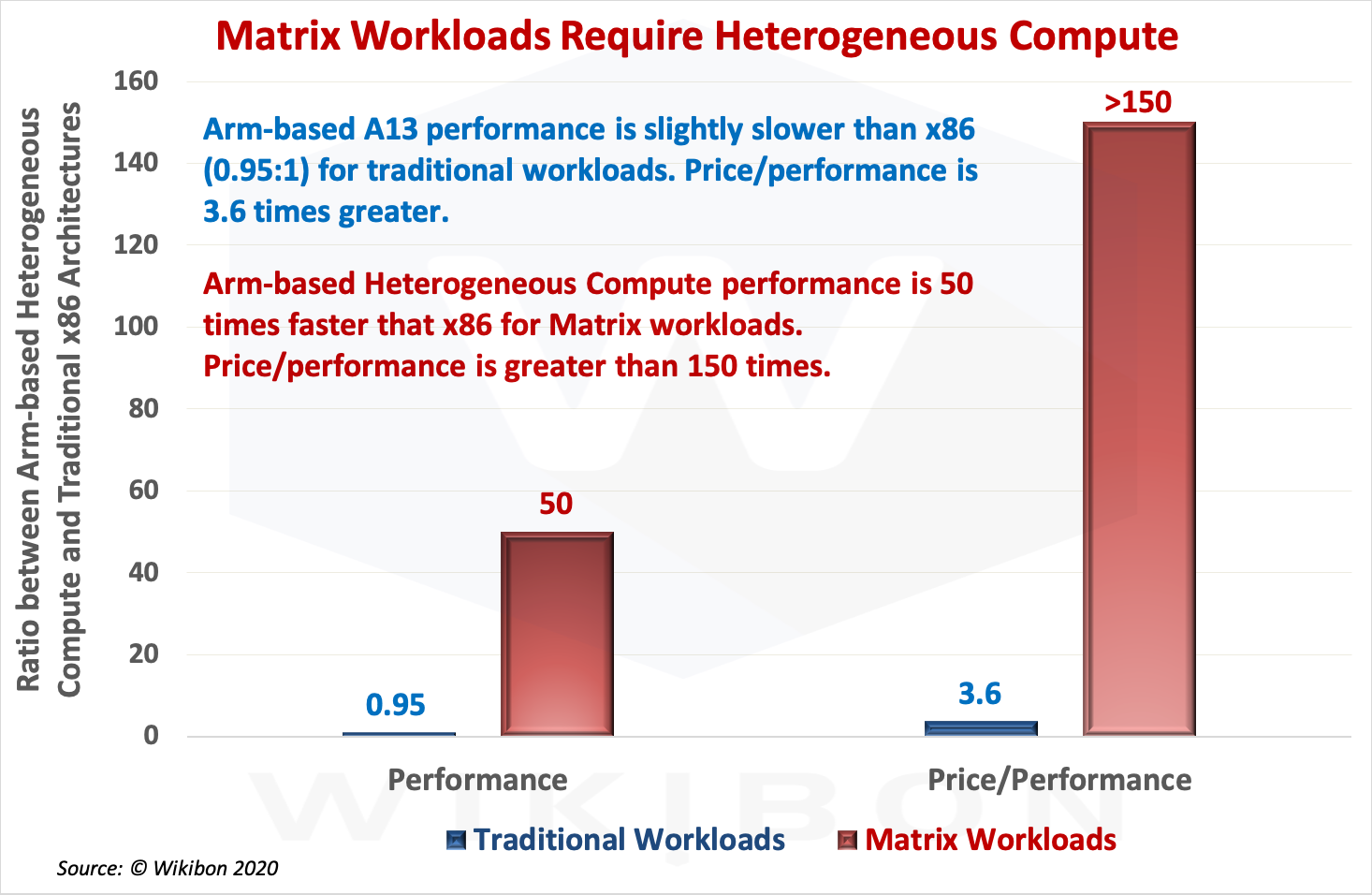
Source: © Wikibon, 2020. See Table 3 in Footnotes and the explanations for details of data sources, assumptions, and calculations.
The y-axis in Figure 1 is the ratio between an Arm-based Heterogeneous Compute architecture (iPhone 11 Pro Max) and a Traditional x86 architecture (Intel i7-1065G7 PC). The two devices have about the same performance for traditional workloads.
The first set of adjacent columns shows the y-axis ratio for performance. The blue column shows the traditional workload performance, which indicates that the Heterogeneous Compute is slightly slower performance (0.95:1) than the x86. The red column shows the Matrix workload performance running on the Heterogeneous Compute architecture is 50 times better than the x86.
The second set of columns shows the y-axis ratio for price-performance. The blue column shows the traditional workload price-performance is 3.6 times better than the x86. The red column shows the Matrix workload price-performance is more than 150 times better.
Data-led Operational Architecture (DLOA)
Heterogeneous Compute systems supporting Matrix Workloads will need radically different deployment strategies. The traditional IT organizational mindset is to reduce the cost of computing. For Matrix Workloads, the mindset will need to focus on minimizing the cost of data storage and moving data. As a result, processing will move to intercept data at the point of data creation and extract the most value from the data in real-time. The data creation can be at the edge, the mobile edge, a centralized data center, or at a centralized site such as an internet POP. A small subset of extracted data can be stored adjacently to allow additional processing requests from other systems. This subset will also enable data movement to other systems across a modern multi-hybrid-cloud network.
Figure 2 below illustrates the differences between traditional and Matrix workload operational workflows. The top half of Figure 2 shows the conventional data sources sending the data to real-time operational systems and then storing all the original data and extracted data in data warehouses and data lakes.
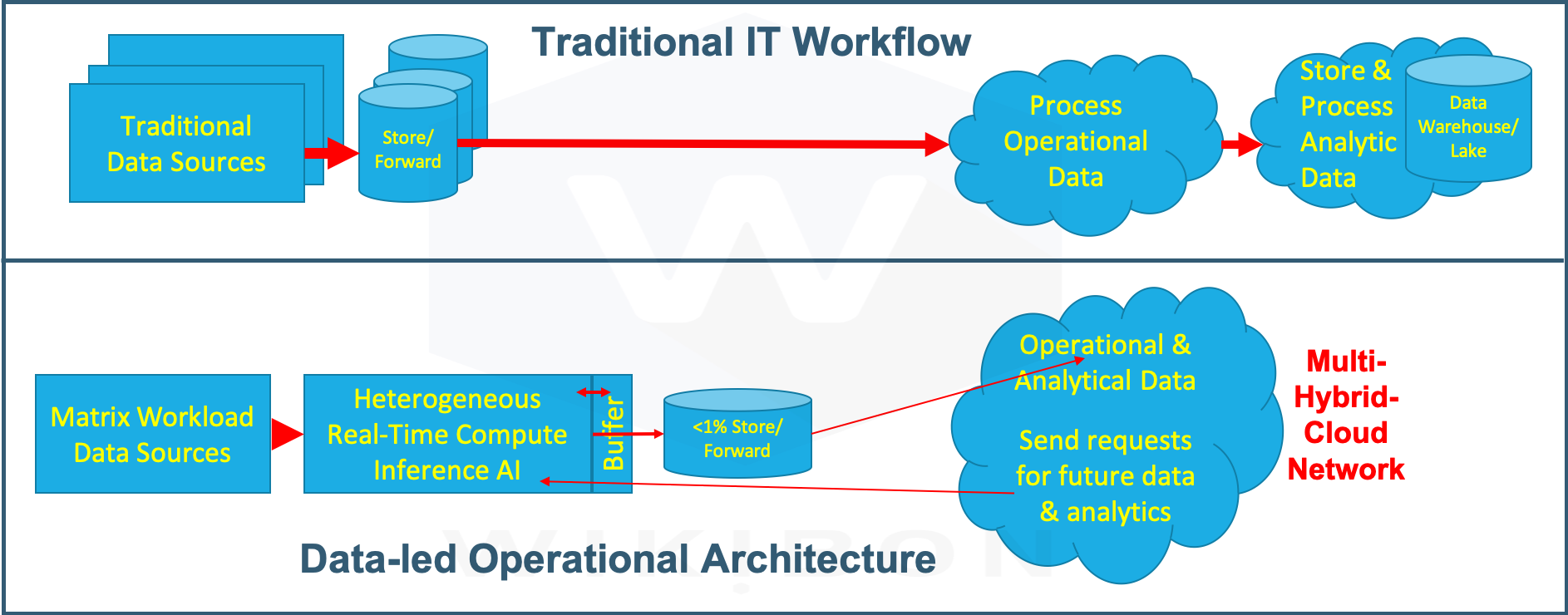
Source: Wikibon © 2020
The bottom half of Figure 2 shows a different way of tackling the problem, more akin to how people operate. Data, often from an increasing number of sensors or data streams, is processed in real-time. Usually, the application is a distributed inference AI module, and a Heterogeneous compute architecture provides the tremendous amounts of computing power required to process the data. The output from each step is kept for a short length of time in a buffer (~ten (10) minutes), to retain context with future results. For example, if an anomaly occurs a few minutes later, all the remaining data in the buffer can be saved and sent centrally for compliance and technical review. The data in the buffer is continuously overwritten.
The application handles the requirements for analysis and additional data. The data from specific rarely occurring situations, for example, could be saved to help development in fine-tuning or extending the AI inference code. Applications can be updated to handle requests for short-term real-time analytics. The retained data is less than 1% of the original data, usually much less than 1%. This data contains extracted information of value. Where possible, workflow designers will place compute resources close to the primary data and avoid data movement. When necessary, the multi-hybrid-cloud network will secure and transport just the final data to other places that need it. In a data-led enterprise, other locations will pay for the transfer.
Heterogeneous Compute Vendors
The leaders in Heterogeneous Compute are currently mainly consumer-led vendors, which utilize design licenses from Arm Inc. Tesla also built its HW3 HC system using Arm components and its own NPU design. The only other HC vendor is an early pioneer, MobilEye, which was acquired by Intel in 2017.
The performance of Arm-led systems now equals or exceeds traditional x86 systems. Wikibon expects Arm-led hardware, frameworks, and software to dominate the Heterogeneous Compute segment over the next decade, both for distributed & Edge computing and for large centralized clouds. The section below entitled “The Importance of Arm Design” has an additional analysis of Arm Ltd. Assuming that x86 vendors continue their current design and manufacturing strategies, this research concludes that 72% of enterprise server spend will be on Arm-based servers by the end of the decade.
Data-led Strategies
People are experts in filtering vast amounts of data at the source. They focus on filtering out what is essential from the array of visual, audio, olfactory, taste, and tactile sensors that bombard us with data. The human brain reaches conclusions in milliseconds through the neural architecture of the brain. People continuously learn to improve filtering processes. They preserve important events as memories and discard the rest of the data.
Enterprises are struggling to become data-led organizations. Part of the problem is there is so much data. Moving it is time-consuming, expensive, and removes context. The ideal is to filter at the point and time that data creation occurs, use it to automate local processes, and inform remote processes. The problem is that current computer architectures are not able to handle these types of real-time workloads with enormous amounts of data. We need designs that operate more like the human brain and filter data at the source.
In earlier research, Wikibon calls these workloads Matrix Workloads. This research focusses on Heterogeneous Compute (HC) architectures, which can process two (2) orders of magnitude more data in real-time than traditional designs within the same cost envelope. Examples of Matrix Workloads include systems of intelligence, real-time analytics, AI inferencing, random forests, robotics, autonomous vehicles, and many others. Wikibon projects the growth of Matrix Compute revenue as 42% of worldwide enterprise compute by the end of this decade. This projection assumes there is no significant change in x86 vendor strategies.
The strategic importance of Heterogeneous Compute architectures is a vital tool in the journey as a data-led enterprise. There are many other tools required. For example, the management of data flows and compliance needs DataOps tools. And, a multi-hybrid-cloud network is necessary to transport smaller amounts of data faster and securely. But at the heart of a data-led enterprise is the ability to extract the value from data in real-time where the data is created, and automate.
Defining Heterogeneous Compute Architecture
This section is technical. The NPU sub-sections are a new and essential topic that deserves allocating time to understand. The final subsection, “Heterogeneous Compute Architecture Examples,” is very technical. There is a “Bottom Line Summary” at the end of this section, which summarizes the research findings.
Why a New Architecture is Necessary
Traditional architectures focus on the CPU as the main component and have focused on providing more cores, more CPUs, faster CPUs, and DRAM. Sometimes GPUs are added. PCIe networking offers bandwidth. The intermediate storage is DRAM. This architecture is not able to process real-time Matrix Workloads at either the required latency or a reasonable cost.
Heterogeneous Compute architectures (HC) allow a more flexible approach in providing a wide range of processor types and providing flexible, very low-latency connections between these processors. The bandwidth and intermediate storage are provided by SRAM, which is lower-latency and higher bandwidth than PCIe. The parallelism and low-latency high-bandwidth enable most Matrix Workloads to process at least an order of magnitude faster at two orders of magnitude lower cost.
Definition of Heterogeneous Compute (HC) Architecture
Wikibon defines HC as a combination of CPUs, accelerators, NPUs, GPUs, and other components such as ASICs together with a flexible, very low-latency high bandwidth connection and intermediate storage between the different elements. The operating system manages the use of resources to meet the processing, bandwidth, and latency requirements of Matrix Workloads.
The major components in a Heterogeneous Compute architecture are as follows:
CPUs
Scalar processing is significant in Matrix Workloads. Not all algorithms in Matrix Workloads can utilize GPUs or NPUs. In general, these workloads have a substantial amount of scalar integer and floating-point arithmetic for algorithms that do not benefit from machine learning.
Accelerators
Offloading certain high-overhead functions to accelerators can improve CPU scalar processing. An Example is an accelerator to speed up encryption. For Matrix Workloads, arithmetical accelerators are essential. For example, the Apple A13 AMX accelerators improve floating-point arithmetic by a factor of six. A complex of processors can be adapted for a particular Matrix workload.
x86 had a large number of specialized instructions added to the architecture, which provide a large number of accelerators. The difference in the x86 approach is that every processor has these accelerators, and it offers processor-first general computing. The HC approach allows greater flexibility in matching the design to the workload.
GPUs (Graphical Processor Units)
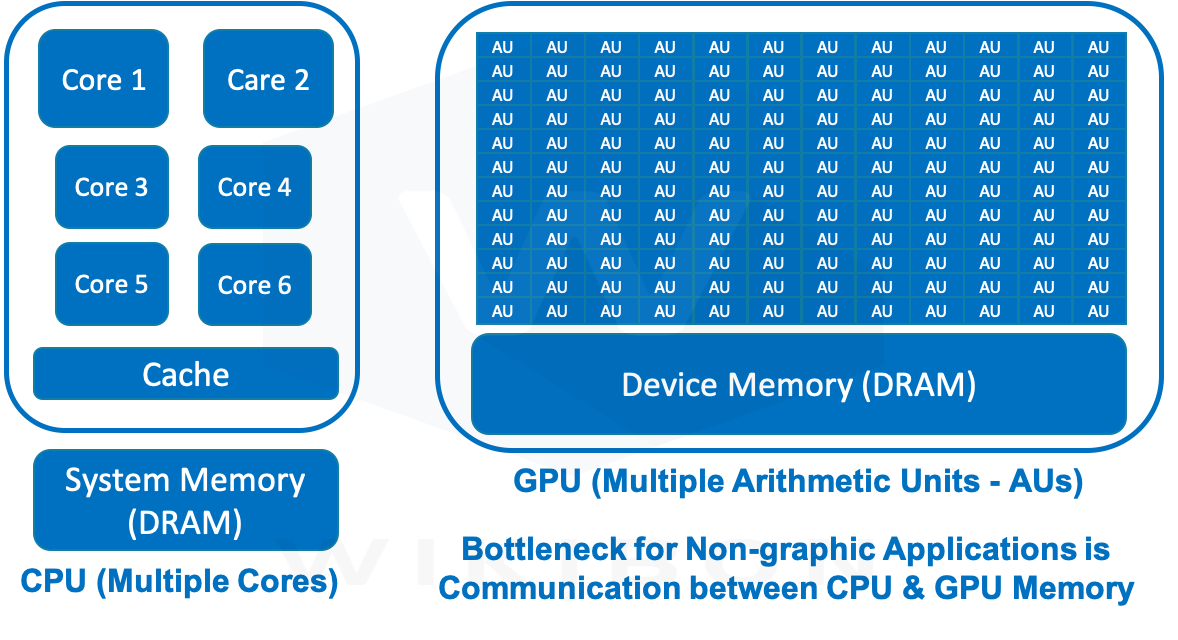
Source: Wikibon 2020 (Adapted after Jill Reese & Sarah Zaranek).
Figure 3 shows how GPUs are different from CPUs. GPUs have hundreds of simple arithmetic units. A GPU can offload or accelerate an application if it is computationally intensive and breaks into hundreds of independent work elements.
The main task of GPUs is to render images, animations, video, and video games to screens on PCs, smartphones, and game consoles. 2D and 3D graphics utilize polygons. Polygon transformation calculations need fast floating-point operations. The array of GPU AUs shown in Figure 3 provides that capability.
Some non-graphic applications can also use the raw power of GPUs. However, the GPU architecture is not ideal for most Matrix Workloads. Most do not use polygons, and therefore do not use many floating-point operations. Integer arithmetic is much faster and much less power-hungry than floating-point.
GPUs work best with non-graphic applications when they are loaded up with work and then process it. Batching can achieve this. GPUs work best when batch sizes are large, e.g., 256.
However, the real-time element of Matrix Workloads changes the emphasis from batch-throughput to low-latency task completion. The appropriate batch size is one (1). However, the new bottleneck is moving, loading, and unloading data in and out of the GPU. As a result, the GPU bottleneck for Matrix Workloads is the memory-to-memory communication between the system memory and the GPU memory, shown in Figure 3. If IT operations attempt to add additional GPUs, this results in poor scaling and lowers the utilization of the GPUs.
For some years now, smartphones and iPads have run consumer Matrix Workloads using Neural Processing Units (NPUs). The next section describes the NPU and why it is more efficient than a GPU for most Matrix Workloads.
Neural Processors Units (NPUs)
Neural networks (often known as artificial neural networks) are computing systems that reflect the structure of the human brain. Neural network units (NPUs) are a very recent addition to computing architecture designed to run Matrix Workloads far more efficiently.
Google employees have contributed significantly to neural network theory and in developing hardware. For example, Ng and Dean at Google created a breakthrough neural network that “self-learned” to recognize higher-level concepts from unlabeled images.
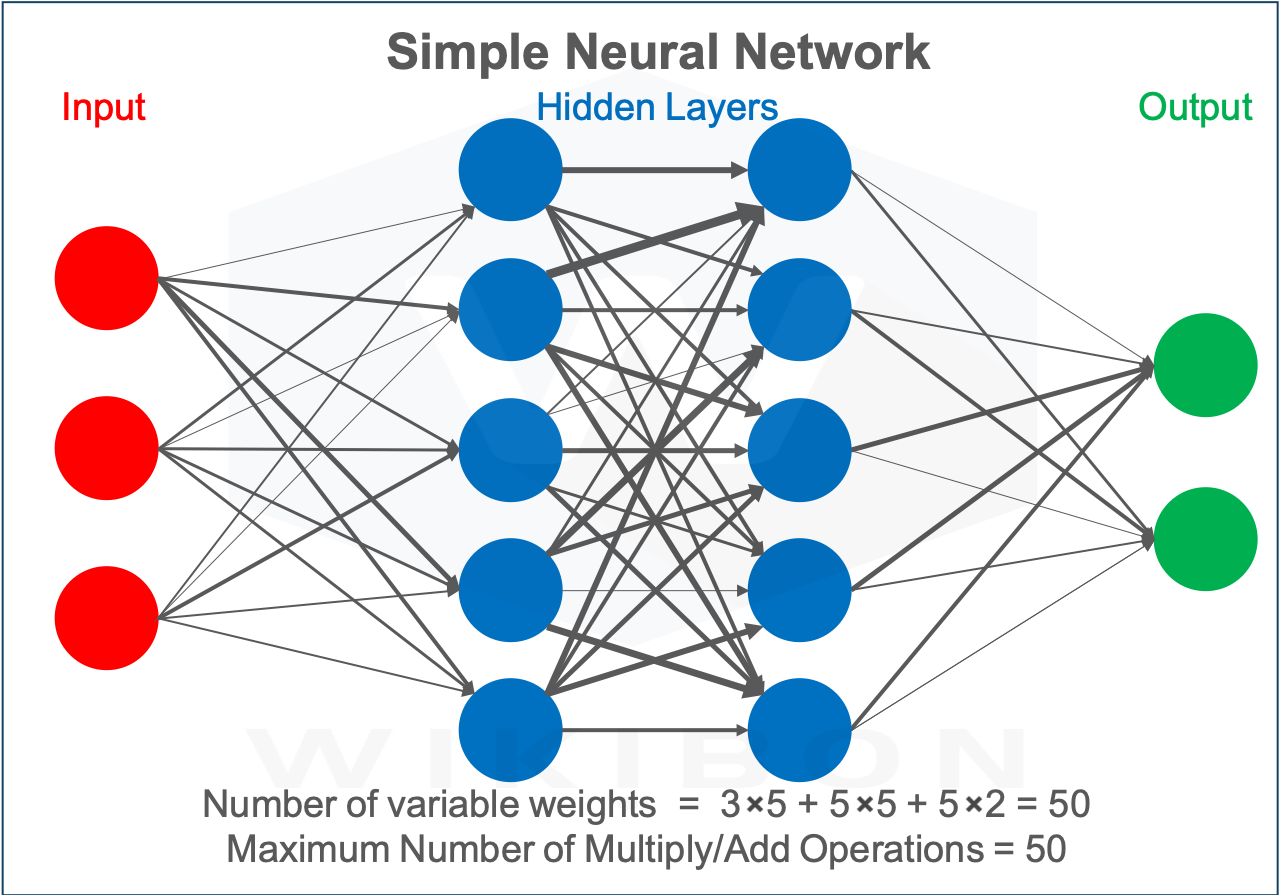
Source: © Wikibon 2020
Figure 4 to the left shows a simple neural network. The input nodes in red receive initial inputs from software or attached devices. Each node or neuron in the two blue hidden layers and the green output layer receives data from the neurons to its left.
In the simple example in Figure 4, these inputs are multiplied by the weights, which are portrayed by the thickness of the connections between two neurons. Every neuron adds up all the data it receives from the neurons to the left. If the sum exceeds a threshold value, the neuron fires, and triggers the neuron(s) connected to it (the neurons to its right in Figure 4). Almost all the calculations are multiply/add operations and go from left to right.
After the inputs neurons have sent the data to the next layer in the first cycle, a continuous process loads the data and weights for the next cycle. Every cycle, the system loads small blocks of data and weights as inputs, and short blocks of data are unloaded from the outputs. For an enterprise example, the Tesla FSD HW3 system has a 96-by-96 input array and operates at 2GHz. The total operational throughput of the two NPUs is 96 × 96 × 2 operations × 2GHz (2 109) × 2 NPUs = ~73 TOPS. TOPS are Trillions of Operations Per Second.
The number of neural network nodes and connections is usually much more extensive than in Figure 4. Integer multiply/add operations are usually over 99.5% of the code. Also, integer operations are quicker and consume less power than floating-point. Using 32-bit integer multiply and 8-bit integer only takes 0.2 pico-joules of power. The power and space requirements are reduced by a factor of over three compared with a Floating-Point GPU. Integer math is accurate enough to meet the needs of most neural network applications.
Why NPUs Need SRAM
The total amount of data input and output across the two NPUs in the enterprise Tesla HW3 system is approximately 0.5KB × 2GHz (109) x 2 NPUs = 2 TeraBytes/second. The bandwidth requirement is at least 4 Terabytes/second, which cannot be handled by DRAM operating in the range of approximately 64 Gigabytes/second. As a result, the system deploys 64 Megabytes of SRAM. Also, SRAM only consumes 20pj of power to move 32KB of data, compared with 100 times more energy with DRAM (2000pj).
The 64MB is enough SRAM to hold the neural net programs, the inputs, weights, and outputs. The design of the SoC can include SRAM on the die.
The disadvantage of SRAM is that it costs much more than DRAM and is about 1/3 less dense. SRAM is at least an order of magnitude better in both bandwidth and power consumption than DRAM. Apple, MobilEye, and Tesla all implement a significant amount of SRAM with the NPUs and HC.
Even though the next generation of processors (such as the IBM POWER system and the AMD servers) have PCIe Gen4, and the bandwidth is double that of PCIe Gen3, this is still not sufficient bandwidth to power NPUs. You also have to take into account that the amount for the next generation of machines will be in the order of 10-100s of TeraBytes/second and grow to PetaBytes/second.
The HC architecture can use smaller and faster NPUs, which scale much better than GPUs for most Matrix Workloads. The section “Measuring Performance & Price-Performance” will show it is much less costly as well.
Training NPUs
There are three main neural network training methods, supervised, unsupervised, and reinforcement. The most common is supervised training, which gives feedback on whether the result is correct or incorrect. This training needs large amounts of labeled data.
Back-propagation is a set of algorithms to assist the training of a neural network to recognize events or objects. The system compares the actual output with the expected output of the neural network. It then modifies the weights (thickness of the lines in Figure 4) to reduce the difference. The network works backward from the output units through the hidden neuron layers to the input neurons. Over time, back-propagation allows the system to learn by making the differences smaller and smaller, and eventually to an exact match. At this point, the neural network has “learned” the correct output and is ready for inference testing. This training process is part of the application development process, needs large amounts of labeled data, and is almost always a centralized function.
The output of AI development is the inference code, which will usually be 99% of the total compute over the lifetime of an application. The inference code does not learn. If the inference code receives the same inputs, it produces the same result every time, which is essential for compliance purposes. Tesla uses this fact to self-check the hardware is running correctly by sending all the inputs to both processors and ensuring that the results are the same.
Although NPUs are new, there are a large number of NPU designers and suppliers. These include Alibaba, Amazon, AmLogic, Apple, Arm, Flex Logic, Google, Graphcore, Microsoft, NPX, Qualcomm, NationalChip, Samsung, RockChip, Tesla, and others.
Other Heterogeneous Compute components
These include DPU (Data Processing Units), DisplayPUs (Display Processing Units), ASICs, and FPGAs. There is plenty of room for future developments.
DPUs offload data-centric tasks from the CPUs, including data transfer, data reduction (compression & deduplication), security & encryption, checking data integrity over time, analytics, and automation. Companies such as Pensando are developing DPU solutions.
Display PUs focus on offloading graphics management functions from the GPU. DPUs are particularly useful in Virtual Reality (VR) applications, a very challenging real-time Matrix workload.
Apple A13 Heterogeneous Compute Architecture
In this research, we have focused in-depth on the Apple A13 SoC as an early example of Heterogeneous Compute architecture. In an adjacent study, Wikibon looks in detail at the enterprise Tesla FSD, which is an advanced enterprise HCA.
Figure 5 below is a die layout of a Heterogeneous Compute SoC, the Apple A13. The components of the system are six processors, including accelerators, which take 30% of the processor real-estate. There is also a GPU, which takes up 41%. The components that turn the SoC into a Heterogeneous Compute architecture are the NPU (10% real-estate) and the System-level Cache and 48 MB of SRAM (19% real-estate).

Sources: Wikichip Apple Arm-based A13 Die Layout downloaded by Wikibon 3/14/2020. Wikibon 2020 calculations & additional graphics.
As we learned in subsection “Neural Processors Units (NPUs)” above, the most common operation in a neural network in inference mode is the multiply/add operation, over 99.5% of the total.
The total amount of SRAM in the Apple A13 is 48 Megabytes, which costs in the order of $30 for volume purchases. SRAM allows a bandwidth between the components of greater than 5 Terabytes/second, compared to a normal range of about 64 Gigabytes/second between main memory and components. The most common operation in the NPU is the multiply/add operation, which completes in 1 cycle. The programs, weights, inputs, and outputs can be all shared across the SRAM. The NPU and CPUs are kept busy. We have assumed that the GPU is not used to keep the power below 6.2 Watts.
This architecture dramatically improves the amount of data that is processed. Without the NPU, accelerators, system-level cache and SRAM, the Apple A13 CPUs would operate at 12 GHz, or 0.012 TOPS (see rows 17 in Footnotes2 Table 3 below). With the Heterogeneous Compute components, the total throughput for Matrix Workloads (see rows 24 & 25 in Footnotes2 Table 3 below) is 6 (NPU) + 1 (CPUs + accelerators) = 7 TOPS. The increase over a non-HCA Apple architecture is 7 ÷ 0.012 = >500 times. Again, the NPU is the reason for this increase in performance for Matrix Workloads.
The next section analyses the performance and price-performance of traditional x86 and Heterogeneous Compute architectures.
Bottom Line Summary: Defining Heterogeneous Compute Architecture
Wikibon defines HCA as a combination of CPUs, accelerators, NPUs, GPUs, and other components such as ASICs together with a flexible, very low-latency high bandwidth storage and interconnection between the different elements.
Heterogeneous Compute architectures can support Matrix Workloads with NPUs, accelerators, and improved integration of all other components with SRAM and a consistent system-level cache. SRAM provides the storage, bandwidth, and low-power that can drive the NPU(s) at high utilizations, and interconnect with the other components.
Apple is leading the rapid adoption of Heterogeneous Compute architectures with the addition of NPUs into Apple Arm-based mobile & tablet devices. Apple is shipping consumer scanning Lidar (Light Detection and Ranging) and is using NPUs to drive consumer 3D AR Matrix Workloads.
Apple and Google are now using NPUs to radically improve the consumer software capabilities of facial recognition, consumer photography, video, audio, and virtual reality services. The increasing number of developers for IoS and Android is developing Matrix applications at a rapid rate, including gaming applications.
The increase in performance of an Apple A13 processor with Heterogeneous Compute architecture features compared with the performance of the A13 without the HCA features is >500 times for Matrix Workloads.
The increase in Matrix workload performance with NPUs is much greater than GPUs, with much less use of real-estate on the SoC. Multiple NPU processors can easily be added, which is not practical for GPUs.
GPUs for graphical output to screens will continue mainly unchanged, at least for a time. Many benchmarks are using a well-accepted metric, frames/second (FPS). More FPS means better user experience. For gaming applications, the user has improved chances of success if the frames/second are faster. Graphical output uses for NPUs are likely to develop over time, as new algorithms develop.
HCA vs. x86 Performance & Price-Performance
This section is a technical and detailed performance and price-performance comparison between a Heterogeneous Compute architecture in the Apple iPhone 11 Pro Max and the traditional Intel i7-1065G7 10th Gen latest Ice Lake PC architecture. This section is detailed and technical. Readers are welcome to skip over the detail and can read the “Bottom Line Summary” subsection at the end of this section.
Methodology
The exercise here is to compare the performance and price-performance of a traditional x86 architecture against a Heterogeneous Compute architecture. These comparisons are analyzed for traditional workloads and real-time Matrix (inference) workloads. Estimating and measuring performance is a science and an art. It is especially tricky when you are dealing with CPUs, GPUs, and NPUs from different system architectures and running different workloads.
The outcome of these comparisons is to help reach a reasonable estimate of performance and price-performance for traditional workloads and Matrix Workloads running on Heterogeneous Compute vs. traditional x86 architectures. If the differences are significant, it will support the argument that fundamental shifts in system architecture will take place. Factors such as the changes required to system software and applications will add significant friction, and lengthen the time for these fundamental shifts to happen. However, the larger the benefit, the better the business case for removing the resistance, and the quicker the development of more advanced systems and application software.
The workload chosen is a facial recognition system using Apple TrueDepth Technology. Yes, I am aware that there is no available version of this technology from Apple at the moment. It is in the noble tradition of thought experiments. The full details of this Matrix workload can be found in Footnote3 in the Footnotes section below. In this experiment, you are the manager of the location and have the responsibility of choosing the platform to run this system. Part of the information required to select the platform is the performance and price-performance of the options.
Architecture Comparisons
Figure 6 below shows the processor die layout of the traditional x86 Intel 17-1065G7 processor on the left. On the right is the die layout of the Heterogeneous Compute Arm-based Apple A13 processor. The plan is similar to the analysis in Figure 5 in the “Heterogeneous Compute Architecture Example” sub-section above.
The Intel i7-1065G7 processor SoC is a traditional x86 architecture used primarily in entry to midsize mobile PCs. The Gen 11 GPU has an increase from the previous GPU generation from 24 to up to 64 execution units. These components, together with four (4) Sunny Cove CPUs, interconnect with each other through the system-level cache, the ring-interconnect, and the 8MB L3 last-level SRAM caches (LLC). The total SRAM is 17 Megabytes. The communication between the SoC and the DRAM has a memory bandwidth of about 64 Gigabytes/second.

Sources: Wikichip Intel i7-1065G7 Die Layout download by Wikibon 3/14/2020. Wikichip Apple Arm-based A13 Die Layout download by Wikibon 3/14/2020. Wikibon 2020 calculations & additional graphics.
On the right of Figure 6 above is the Arm-based Apple A13 SoC with a Heterogeneous Compute architecture. There is a GPU, two fast Lightning CPUs, and four slower Thunder CPUs, and an NPU. They are all interconnected through a large system-level cache with a significant amount of SLC SRAM. The total amount of SLC SRAM on the A13 Soc is 48MB, which is much higher than traditional x86 architecture. As a result, a bandwidth of 5 TeraBytes/second can be achieved between all the Heterogeneous Compute elements, which is about 100 times faster than the traditional x86 Intel processor.
The most important conclusions from comparing the two architectures in Figure 6 above are listed below.
- GPUs take up a large amount of space. The Intel GPU takes up 57% of the processor space, and the Apple GPU takes 41%. Space means real-estate, transistors, and power. Adding additional GPUs to the SoC to execute Matrix Workloads is not a practical option.
- The amount of space dedicated to processors on the die is 45 mm2 for Apple, less than the 72 mm2 for Intel. The Apple A13 die fab process is two generations more advanced, using 7nm with EUV (Extreme UltraViolet). As a result, the transistor density is much higher for Apple at 116 million/mm2. Intel was aiming at an ambitious density of 108 million/mm2 for its 10nm fab but had to cut back to 67 (estimated) million/mm2 because of production yield and quality problems. The number of processor transistors in the two architectures is about the same, which means the expected performance of both CPU architectures for traditional workloads is likely to be similar.
- The A13 power requirement is 6.2 Watts, compared with 25 Watts for the Intel processor. For iPhones, Apple has focused on using the advanced 7nm EUV fabrication to reduce power consumption. Apple has made general statements that A13 performance has improved by 20% and power by 35% compared with the previous A12 processor. There is plenty of space on the chip to add more functionality for iPads, which can run with more power, up to 15 Watts. Our bet is on higher performance higher Wattage Arm-based SoCs for Macs as well!
- The seven sections above lead to an overall conclusion that Arm-based processors like the Apple A13 should deliver about the same performance for traditional workloads as the Intel x86 processors.
- The overall conclusion for Matrix Workloads is that the Heterogeneous Compute architecture of the Apple A13 with NPU is potentially much faster than the Intel x86 processors.
Please see the caveats in Footnote1 below for any of the analyses in this section.
Comparing Performance & Price-Performance Apple vs. x86
Table 1 below is a summary of Table 3 in Foonotes2 below. It compares the performance and price-performance of traditional x86 architecture and Apple Arm-based Heterogeneous Compute architecture. The performance workloads are traditional (shown as yellow rows) and Matrix (shown as purple rows).
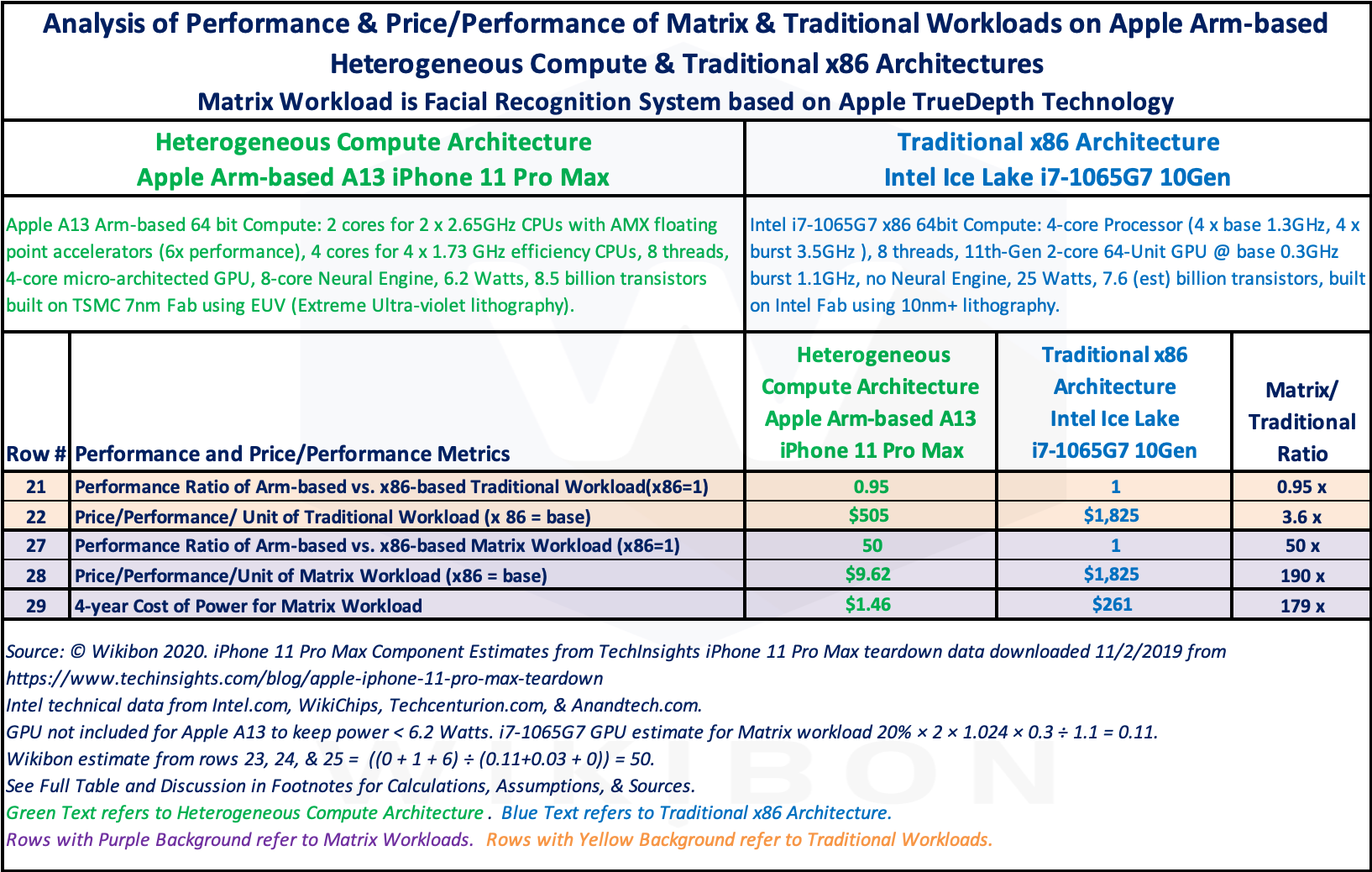
Source: © Wikibon, 2020. See Table 3 in Footnotes2 for additional rows and for explanations, details of data sources, assumptions, and calculations.
The details of the Apple Arm-based Heterogeneous Compute architecture are in the second and third rows of Table 1, on the left-hand side, in green. The product is a consumer iPhone 11 Pro Max. The details of the x86 Intel Ice Lake i7-1065G7 10Gen PC system are opposite, in blue.
Row 21 in Table 1 shows the performance ratio between the Apple HCA iPhone in green, and the x86 in blue (set to 1). The workload is traditional; the ratio is 0.95:1. The basis of this is rows 19 and 20 of Table 3 in Footnotes2, from 2019 Geekbench single and multi-core scores, and described in notes following Table 3. This result is not a surprise, as the performance of Arm-based systems has caught up with Intel, and in some datacenter areas, exceeded it.
Row 22 in Table 1 shows the price-performance comparisons for traditional workloads. They are based on Table 3 below, rows 2-10. The price of the x86 Intel system is estimated as $1,825 (row 10 of Table 3) and the price of a system based on the Apple iPhone 11 technology is estimated as $505 (calculated from the actual price (row 10 in Table 3) of $482 ÷ 0.95 from row 22 of Table 1). The price-performance ratio is 3.6:1 in favor of Apple, as shown in the last column of row 22.
Row 27 in Table 1 shows the performance ratio of 50 for the Apple HCA iPhone in green to the x86 in blue (set to 1). The workload is Matrix, and the ratio in the last column of row 23 is 50:1. The calculations are complex and are spelled out in the notes in subsection “TOPS Calculations for Matrix Workload: Rows 23-27” after Table 3 in Footnotes below. TOPS is Trillions of Operations per Second and is a “gee-wiz” number used in GPU marketing. The GPU claims have been modified in this table to reflect the performance in a real-world real-time Matrix workload. The TOPS ratings in Row 26 of Table 1 are the sum of GPU + CPU + NPU. In the case of the Apple HCA, this is 0 + 1 + 6 = 7, and in the case of the x86 this is 0.11 + 0.03 + 0 = 0.14. The ratio is 7 ÷ 0.14 = 50. The reason for this large number is the efficiency of the NPU with SRAM, compared with the GPU in real-time Matrix Workloads.
Row 28 in Table 1 shows the price-performance comparisons for Matrix Workloads. It is calculated by row 22 ÷ row 27. The price-performance ratio in the last column is 190:1. The Apple Arm-based system with NPUs is over two orders of magnitude less expensive than a traditional x86 platform.
Row 29 in Table 1 show the 4-year cost of power for the different architectures running Matrix Workloads. The calculations include the cost of power supplies, the cost of electricity at $0.12 per kWh, and a PUE (Power Usage Effectiveness) ratio of 2. The ratio between the two architectures is 179 times, again over two orders of magnitude less power than a traditional x86 platform.
Other Heterogeneous Compute Platforms
Other vendors for Neural-network Processor Units (NPUs) include Alibaba, Amazon, AmLogic, Apple, Arm, Flex Logic, Google, Graphcore, Microsoft, NPX, Qualcomm, NationalChip, Samsung, RockChip, Tesla, and others. The vast majority of these vendors have strong relationships with Arm and are Arm licensees.
One exception from this list is Nvidia. Wikibon expects that Nvidia will fill this gap within 18 months and include NPUs as part of its CUDA software framework. Nvidia is also an Arm licensee, with long-term projects with Arm.
Bottom Line Summary: HCA vs. x86 Performance & Price-Performance

Source: © Wikibon, 2020. See Table 3 in Footnotes and the explanations for details of data sources, assumptions, and calculations.
Table 2 on the left is a summary of the performance and price-performance ratios between Apple Arm-based Heterogeneous Compute and Traditional x86 architectures. The traditional workload is shown on the yellow row and the Matrix workload on the purple row. Table 2 is the source of Figure 1 in the Executive Summary above.
The key conclusions are:
- Arm-based A13 performance is slightly slower than x86 (0.95:1) for traditional workloads. Price-performance is 3.6 times greater.
- Arm-based Heterogeneous Compute performance is 50 times faster than x86 for Matrix Workloads. The price-performance is greater than 150 times.
- The cost of power and cost of power requirements for Matrix Workloads are two orders of magnitude greater than for traditional x86 architectures.
The Importance of Arm Designs
Disaggregation of Processor Design and Manufacture
A number of vendors have indicated that “enterprise” computing requires higher levels of robustness and recovery than “consumer” devices. This is true. However, these vendors have missed the fundamental changes in the processor industry. The traditional vertical integration of processor design and production has changed. The manufacturing and production of processors are now dominated by companies such as TSMC and Samsung. The design of processors is dominated by Arm Ltd, owned by SoftBank out of Japan.
Arm has a portfolio of qualified designs for standard functional processor components. These are also qualified for manufacturing by the fabs. Processor vendors, such as Apple, AWS, Fujitsu, Qualcomm, Microsoft, Nvidia, Samsung, Tesla, etc. can focus on the innovation in (say) one or two components and take standard components for the rest. Arm Ltd. has already introduced NPUs. Arm has introduced Neoverse E1 & N1 servers for traditional workloads into its design portfolio. AWS, Fujitsu, Microsoft, Nvidia, Tesla, and others are already using Arm-based processors in enterprise high-performance high-availability environments.
Benefits of Disaggregation
The result of the bifurcation of design and manufacture has dramatically reduced the cycle-time of processor innovation. A 50:1 change in performance is a design revolution, not an evolution. The Arm-based design model introduces the benefits of volume at the component level within a processor, rather than at the SoC level. Arm-based processors already account for 10 times the number of wafers made by the worldwide fabs, compared to x86. This volume brings down the cost of Arm-based components and SoCs. Hence the price-performance differences seen the earlier analysis.
This is a much more efficient innovation engine for both consumer and enterprise computing, compared with the traditional 5-year+ integrated processor cycle. Different real-time Matrix Workloads will benefit running on an architecture optimized for that specific type of Matrix workload. Wikibon believes that these resulting innovations will fundamentally change the server and system architectures for this decade and how enterprises distribute computing.
Results of Disaggregation – Inference Servers
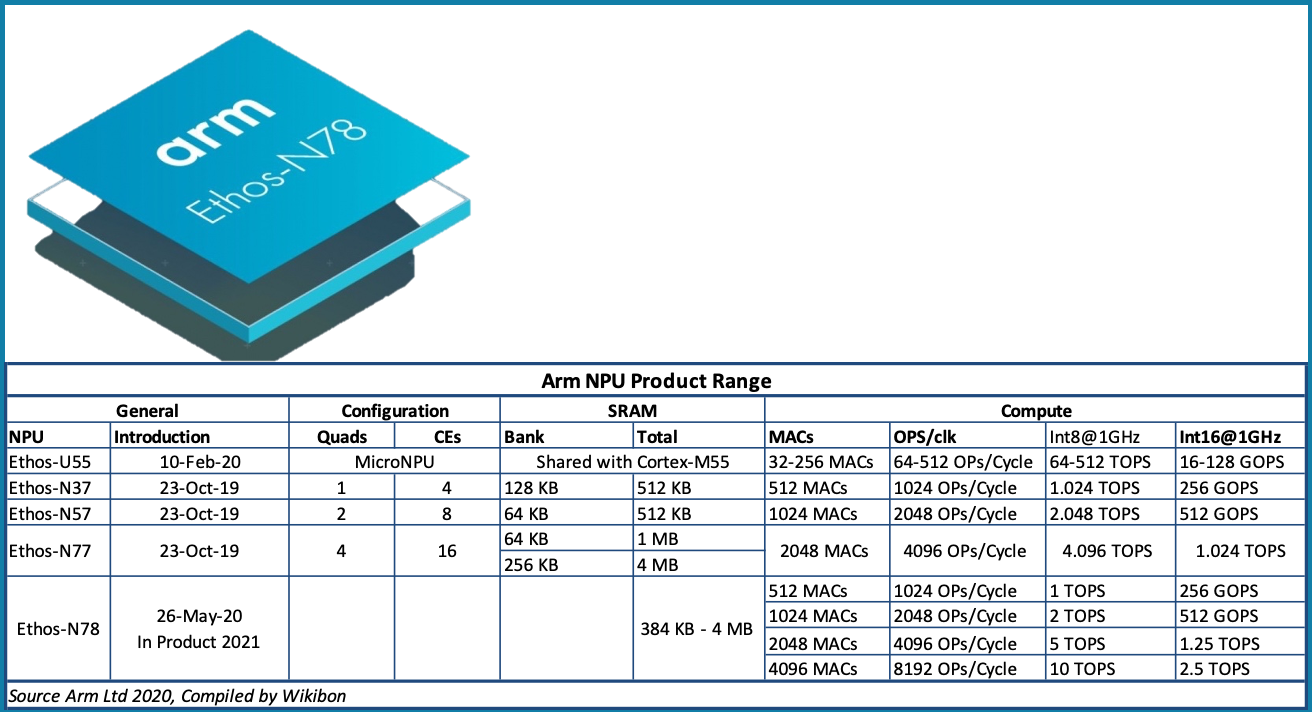
Source: Arm Ltd. 2020, Data Compiled by Wikibon
Inference NPUs are now in volume production. The speed of the introduction of NPUs is illustrated by looking at the range of NPU designs from Arm. Figure 7 shows the current range of Arm NPU designs. Arm introduced its first NPU design as the Ethos-N77 in 2019.
Arm introduced the Ethos-U55 early in 2020. The U55 is a microNPU design suited for small form factors.
The Arm Ethos-N78 was introduced in May 2020, with significantly improved specifications. It now supports 6nm EUV technology at TSMC.
The current weakness of the Arm NPU designs is the support for larger amounts of SRAM. Currently, the limit is 4MB per NPU. Tesla has 32MB SRAM per NPU, with similar amounts in Apple processors. Wikibon expects this will be addressed in a future design releases.
The leaders in Heterogeneous Compute are currently consumer-led development expertise and Arm-led hardware systems. The performance of Arm-led systems now equals or exceeds traditional x86 systems. Wikibon expects Arm-led hardware, frameworks, and software to dominate the enterprise Heterogeneous Compute market segment over the next decade.
Wikibon projects that AI inference systems will grow to be 99% of the AI system spend over the next decade. The development training portion will reduce to about 1%. In earlier research, Wikibon projects that Matrix Workloads will grow to 42% of enterprise compute revenue by the end of this decade.
Results of Disaggregation – Offload and x86 Scale Replacement
About 20% of processing is dedicated to managing storage and networking. This is work that is relatively easy to offload, especially for large cloud datacenters. One example is the AWS Nitro System, which is an underlying platform for EC2 instances that enables AWS to offload storage and networking services. In addition, Nitro helps AWS improve the performance and security of these services. Another example is Mellanox, recently acquired by Nvidia, who are offloading the storage networking on ConnectX SmartNICs with Arm-based processors. Functions such as RDMA acceleration for NVMe over Fabrics (NVMe-oF) storage and high-speed video transfer can be offloaded from the general-purpose CPUs with faster performance and improved security. The offload of specific workloads that can be processed more efficiently on purpose-built Arm-based servers will continue to grow.
Arm-based servers will also have a growing impact on cloud data centers, as parts of workloads are migrated from x86 to Arm-based servers. AWS and Microsoft Azure are well into this process. At Reinvent 2019, AWS announced the AWS Graviton2 processors, which are custom-built by Amazon Web Services using 64-bit Arm Neoverse cores. These cores deliver 40% lower costs for AWS M6g, C6g, and R6g EC2 instances and offer equivalent or better performance.
In addition, Arm has introduced the Neoverse N1 and E1 high-performance architectures as high-performance and low-powered straight replacements for x86 processors. Ampere is now shipping the Ampere Altra, a 64-bit Arm processor with 80 cores based on the Arm Neoverse N1 platform. The power consumption is up to only 211 Watts.
Results of Disaggregation – Market Impact
Figure 8 below shows the impact that lower cost and higher function Arm-based processors will have on the enterprise server marketplace. The total enterprise server marketplace was $76 billion in 2019, and Wikibon projects that it will grow to $113 billion by the end of this decade. The revenues moving to Arm-based processors from the offload of storage and networking functions are shown in blue. The revenues from the introduction of Arm-processors for traditional workloads are shown in green. Finally, the introduction of Matrix Workloads, which will require Heterogeneous Compute architecture is shown in grey.
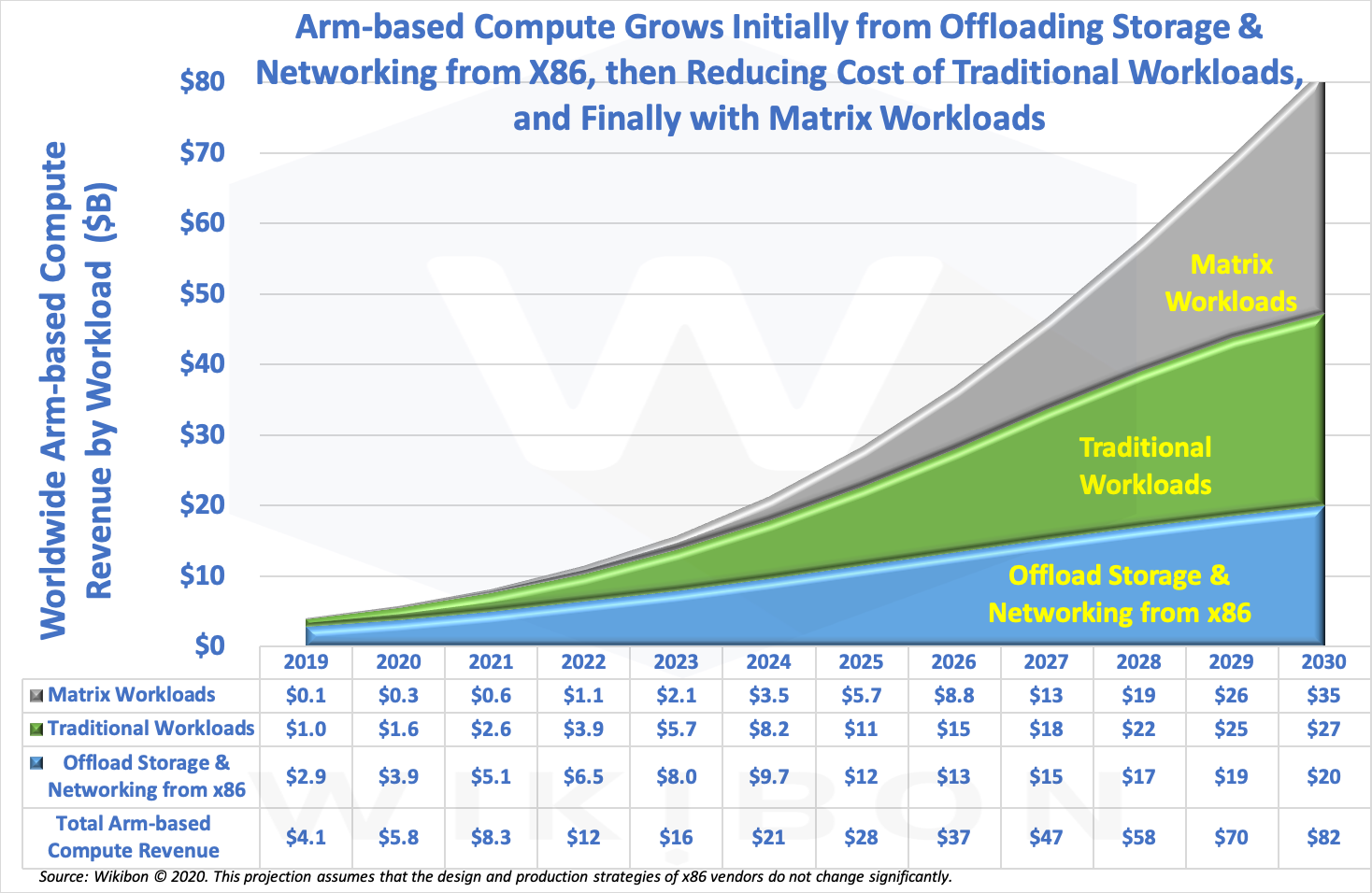
Source: Wikibon, 2020. This projection assumes that the design and production strategies of x86 vendors do not change significantly.
Wikibon projects that 72% of the enterprise server marketplace will be Arm-based servers by the end of this decade. The fundamental reasons for the speed of this migration are the lower cost from volume production, faster innovation of servers built for specific workloads, the better use of fabs, and the reduced barriers from software friction because of the large-scale cloud providers such as Alibaba, Amazon, Google, and Microsoft. It is important to emphasize that the Wikibon projection in Figure 8 assumes the design and production strategies of x86 vendors do not change significantly.
Last but not least, is the fact that Arm Ltd. is a UK-based company owned by SoftBank out of Japan. Many European and far-east countries quietly want to reduce their dependence on US processor technologies.
Bottom Line Summary: The Importance of Arm Designs
The disaggregation of processor design and manufacturing leads to much faster innovation cycles for both consumers and enterprises. Companies such as Apple and Tesla could develop NPU innovations by using Arm-based standard designs for the rest of the system. As a result, the time to innovation is reduced by a factor of 2 or more. This leads to more designs and higher volumes, which in turn leads to lower costs.
The largest cloud providers are leading the migration to Arm-based servers because they have the scale to make the software changes required. The first uses of Arm are to offload storage and networking, the second is to use Arm processors for specific workloads, and the third is the use of Arm-based Heterogeneous Architectures. Wikibon projects that about 72% of server spend will be on a greater variety of Arm-based servers by the end of this decade.
Conclusions
Splitting design and manufacturing has allowed the rest of the industry to innovate faster than x86 vendors in both areas. The leading processor fabs use 7nm with EVA and are well on the way to deploying 5nm. Smaller means a little bit faster and quite a bit better power consumption. Arm is the leading designer with a broad set of processor components, which allows processor vendors to take standard parts and focus their design effort on specific differentiating components. It is important to emphasize that the Wikibon Arm projection in this research assumes the x86 vendors continue with their current strategies.
Heterogeneous Compute Architectures
This research shows that Heterogeneous Compute architectures can run Matrix Workloads at two orders of magnitude lower cost than traditional x86 architectures. The HC architecture is defined by a wide choice of processors and extremely high bandwidth. The highest performance systems from Apple and Tesla include Neural-network Processor Units (NPUs) with large amounts of SRAM to drive interconnectivity and intermediate storage. These systems are able to run Inference AI application 50 times faster than a traditional x86 system with an integrated GPU, and more than 150 times better price-performance. Wikibon projects that five significant changes will result from this dramatic change in the cost of running Matrix Workloads.
The use of GPUs for non-graphical inference workloads will slow over the next five years. They will still be relevant for workloads with polygon transformation. In general, the lower cost and higher performance of NPUs will lead to the development of new methods of deploying them. This trend will accelerate as NPU software frameworks mature, and NPU expertise becomes widely available.
The disaggregation of processor design and manufacturing has led to at least a doubling of the rate of innovation. This has been led by Arm Ltd, a design company. Processor companies such as Apple are able to take standard design SoC components from Arm and focus on innovation such as NPUs to improve the performance of real-time AI inference software. As a result, these applications deliver results in milliseconds compared with multiple seconds.
Tesla was able to build the bespoke HW3 Heterogeneous Compute system, deploy it in less than 3 years using Arm-based building blocks, and achieve a solution that ran 21 times faster than the previous GPU solution. Without disaggregation, it would have taken more than 6 years with enormous risks of failure.
Data-led Operational Architecture
People are experts in filtering vast amounts of data and use Neural Networks to achieve this. Afterward, they remember only what matters and discard the input data. The same is true of genomic computing, which starts with immense amounts of data and reduces it by a factor of more than 100:1 to just an enormous amount of useful data describing the chromosomes and genes.
Tesla is a completely data-led company. It continuously captures 3 billion bytes of data per second from all the vehicles in the fleet that are driving. The HW3 is processing all this data either in shadow mode (where it is comparing its own plan with the drivers’ actual execution) or actually self-driving the car with occasional guidance from the driver. Only exceptional data is fed back, for example, a near miss or accident. Development can ask for specific and unusual data to be captured, for example, to see how drivers deal with large animals in the vicinity. After ten minutes, the data in the buffer is overwritten.
Tesla’s data architecture is a Data-led Operational architecture, as described in Figure 2. The efficiency of this data handling allows Tesla to capture data from the complete fleet of cars. The cost of the 74 TOPS system is about $1,600, and the cost of the cameras and sensors is another about $1,400. For a cost of $3,000 per car, Tesla can capture data from its complete fleet of over a million cars worldwide.
Data-led Strategies
Tesla owns all the data and can explore new ways of using this to expand the traditional vehicle market. For example, Tesla uniquely knows who is driving and how well they are driving and can selectively offer insurance by the minute. Or offer options for places to stay or eat. Tesla broke its relationship with MobilEye because their long-term business interests were not in line, and Tesla designed a computer to ensure it remained a data-led business.
At the heart of a data-led enterprise is the ability to extract the value from data in real-time where the data is created, and automate. Heterogeneous Compute architectures running Matrix Workloads, Data-led operational architectures, and designing end-to-end enterprise data architectures with DataOps tools are all essential elements in establishing a data-led enterprise and culture.
Action Item
IT Executives
Senior executives should evaluate how Heterogeneous Compute Architectures, Matrix Workloads, and data-led operational architectures can assist or initiate an enterprise data-led strategy. Wikibon expects that failure to invest in Data-led Matrix Workloads will lead to a high percentage of business failure in many industries, especially vehicle industries.
Server Vendor Executives
Wikibon expects full level 5 automated self-driving software and hardware to be available in 2026 and beyond. There are approximately 1 billion vehicles of all types in the world. The unit price will be between $2,000 and $5,000 per vehicle. Some segments of the industry, such as military vehicles, will demand much higher prices.
The total TAM is about 4 trillion dollars starting in 2024 and spread over the next 20 years, with an average TAM of $200 billion per year. The upgrade and replacement TAM will be in the order of 10% of the installed base per year. Expertise in government certification and compliance will be at a premium.
There is also an adjacent market of fixed and semi-mobile for industrial and consumer devices of lower unit cost but similar overall TAM.
Software Vendor Executives
Wikibon will discuss Matrix workload software in future research.
Footnotes:
Footnote 1
A word of caution regarding the die layouts: Intel has not released much detailed information about their 10nm + SoCs. Although WikiChips and Wikipedia have excellent and highly knowledgeable contributors, they are not infallible!
Footnote 2
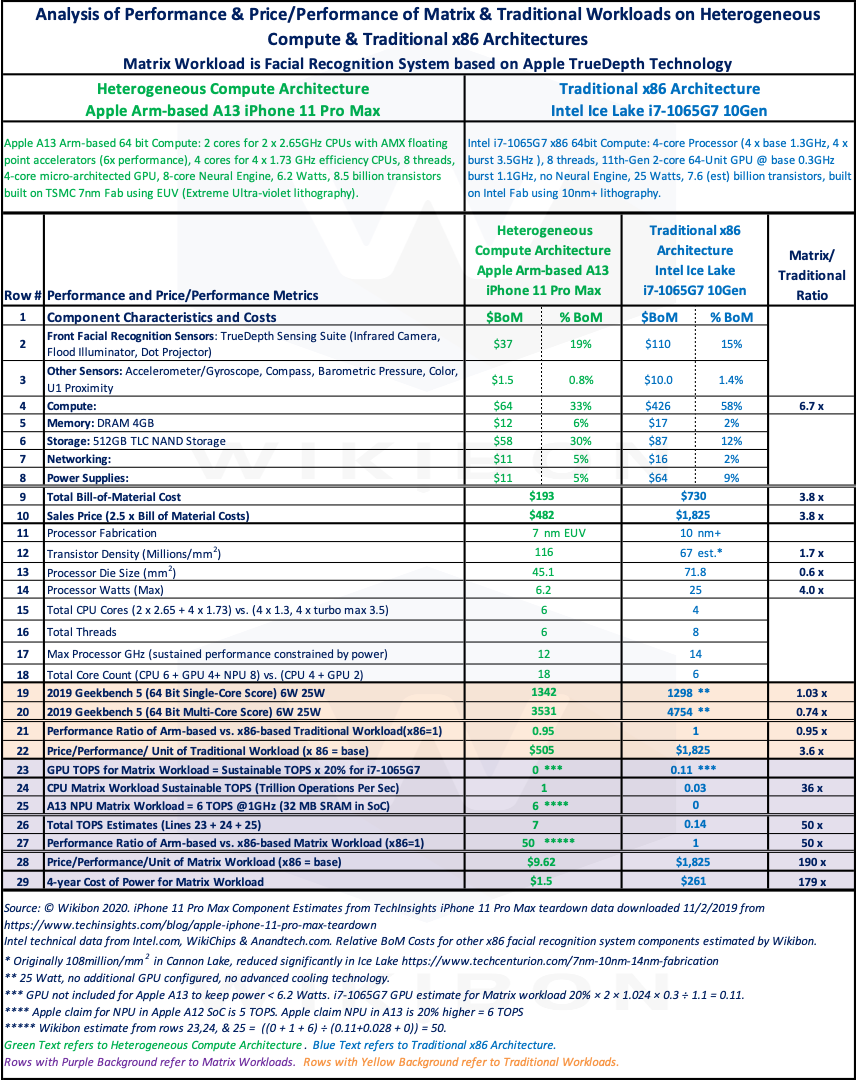
Source: © Wikibon, 2020. The Rows provide details of data sources, assumptions, and calculations.
System Costs: Rows 1-10
Rows 1-8 in the green columns show the teardown costs for the Apple iPhone 11 Pro Max. This research has taken only the components required to create the Heterogeneous Compute server to run the facial recognition software, a Matrix workload. For example, screen costs are not included. The costs are low because of the high consumer volumes for this product.
Row 1-8 in the red-column shows the equivalent costs for an Intel system. The cost for the processor is taken from the Intel website. The other costs were estimated by Wikibon. In general, the cost of attaching components is high on the Intel PC platform because of the Intel architecture and the much lower volumes.
- The Intel PC i7-1065G7 processor is 6.7 times more expensive than the Apple A13 processor.
- The additional PC system components are 2.4 times more expensive than the iPhone components.
Row 9 is the total bill-of-materials cost of the two facial recognition systems, calculated as the sum of rows 1-8.
Row 10 is the expected sales price for each system, assuming that the uplift is 2.5 times line 9 for both systems.
- Overall the facial recognition system with PC components is 3.9 times more expensive than the iPhone components.
- The performance of the two systems for traditional workloads is about the same, as we will discover in the next sub-section.
Benchmark Calculations Traditional Workload: Rows 19-22
This section uses Geekbench, a well-known cross-platform benchmark. It runs single-core and multi-core workloads. Each single-core workload has a multi-core counterpart. There are three workload types. They are cryptography (5% weighting), integer (65%), and floating-point (30%). The assumptions and calculations are as follows:
- All the rows are yellow and evaluate traditional workloads on the two architectures.
- The Geekbench is a cross-platform benchmark, with single-core and multi-core scores.
- We assume that the i7-1065G7 does not have an external GPU, and assume there is no external cooling.
- Row 19 is the single-core Geekbench 5 score for the two platforms at the correct Watts.
- Row 20 is the multi-core Geekbench 5 score for the two platforms at the correct Watts.
- Row 21 for the Apple A13 platform is the (harmonic mean of A13 single-core & multi-core scores) ÷ (Harmonic mean of i7-1065G7 single-core & multi-core scores) = 0.95
- Row 21 for the Intel i7-1065G7 platform is set to 1. For traditional workloads, the A13 is in the order of 5% slower than the performance of i7-1065G7.
- Row 22 shows Price-performance. The sale price of the configurations is shown in row 10. Row 22 = Row 10/Row 21. The price-performance of the Intel i7-1065G7 system is 3.6 times higher than that of the Apple A13 system.
- Conclusions: Arm-based mobile Apple has caught up with x86 mobile in terms of traditional workload performance and is over three times better price-performance.
Future Wikibon research will show that Arm has caught up with x86 datacenter processors, and offers much better price-performance.
There are many benchmarks. There are very few cross-platform benchmarks. Benchmarks are just data points. The analysis of rows 11 – 18 also shows that the traditional workload performance of the Intel and Apple mobile processors are likely to be similar. There will be specific traditional workloads where one system or the other will shine.
The Matrix workload analysis shows a very different story.
TOPS Calculations for Matrix Workload: Rows 23-27
Another metric used to evaluate system performance is TOPS or Trillions of Operations Per Second. The process is to take all the components of a system and add up the TOPS value for each. For example, if a CPU has a TOPS value of 0.5, the GPU has a TOPS value of 1, and the NPU has a TOPS value of 6, the total system has a TOPS value of 7.5. As you might imagine, marketing departments love the simplicity of this metric.
As we said a little earlier, a performance metric is just information. The overall TOPS figure is the maximum rate the system might operate if the workload allows each component to run at 100%. This utilization is, of course, virtually impossible to achieve.
Wikibon research shows that GPUs have the highest TOPS rating and are the biggest culprit in overestimating Matrix workload performance. Wikibon’s methodology is to use this metric as-is for processors and NPUs and adjust the TOPS values of GPUs according to the approximate percentage utilization achievable.
- Rows 23-27 are purple and evaluate matrix workload performance on the two architectures.
- The Intel rates the i7-1065G7 GPU as 1.024 TOPS at a burst rate of 1.1 GHz. However, the guaranteed base rating is 0.3 GHz. Therefore, the guaranteed TOPS is = 1.024 × 0.3 ÷ 1.1 = 0.28 TOPS. A reasonable assumption is that the sustainable throughput for this GPU is about twice the guaranteed rate = 0.28 × 2 = 0.56 TOPS to remain within the 25 Watt power constraint.
- Also, any GPU used for real-time Matrix Workloads would need to have a batch size = 1 setting. This setting optimizes latency, not throughput. However, this setting, as a rough rule of thumb, would mean the throughput would decline to about 10%-20% of the sustainable throughput. We have assumed 20% in the calculations just below.
- The Wikibon assessment of the Intel GPU sustained TOPS rating for real-time matrix Workloads is 0.56 × 20% = 0.11 TOPS. The result is shown in Row 23 in the blue column.
- The Apple A13 GPU is assumed not employed (set to 0 TOPS) to keep the power below 6.2 Watts. The result is shown in the green column of Row 23 in Table 3 above.
- The Intel processors have 4 processors with two threads at 3.5 GHz. The TOPS rating is 2 × 4 × 3.5 ÷ 1,000 = 0.028 TOPS. The result is shown in the blue column of Row 24 in Table 3 above.
- Apple rates the processors with accelerators as 1 TOPS. This is shown in the green column of Row 24 in Table 3 above.
- As the i7-1065G7 has no NPU, the value is 0 TOPS. Apple rates the A13 NPU as 6 TOPS. These are shown in Row 25 in Table 3 above.
- Total TOPS for i7-1065G7 is 0.11 + 0.028 + 0 = 0.14 TOPS. Total TOPS for Apple A13 = 0 + 6 + 1 = 7 TOPS. These are shown in Row 26 in Table 3 above.
- The ratio of TOPS performance A13/i7-1065G7 = 7:0.14 = 50:1. These are shown in Row 27 in Table 3 above.
- Conclusions:
- TOPS is not a good metric for determining the relative performance of Matrix Workloads across different architectures. Wikibon has adjusted the GPU TOPS ratings and improved the accuracy, but it is not a reliable metric.
- The result of this performance study with its imperfections shows that Heterogeneous architectures with NPUs are 50 times faster than traditional architecture with a GPU.
- It is a reasonable and highly likely conclusion that Heterogeneous architectures are an order of magnitude faster than traditional approaches for Matrix Workloads.
Note: AI training workloads are not Matrix Workloads, as it is not real-time. Training workloads are usually batched, and this will increase GPU throughput significantly. Training is a high proportion of AI compute-power at the moment, but inferencing will be far more important over this decade.
Price-Performance Calculations for Matrix Workload: Rows 28
- Price-Performance of Matrix Workload is calculated by taking the sales prices in Row 10 and dividing by the relative performances in Row 27. of (x86 = base). The price per unit of performance is $9.62 for the Heterogeneous Compute and $1,825 for the traditional architecture. The ratio is 190:1 in favor of Heterogeneous Compute.
- Conclusions:
- It is a reasonable and highly likely conclusion that Heterogeneous architectures are two orders of magnitude less expensive than traditional approaches for Matrix Workloads.
Cost of Power: Row\ 29
Row 29 in Table 1 show the 4-year cost of power for the different architectures running Matrix Workloads. The calculations include the cost of power supplies (Row 8), the cost of electricity at $0.12 per kWh, and assumes a PUE (Power Usage Effectiveness) ratio of 2. The ratio between the two architectures is 179 times, again over two orders of magnitude less power than a traditional x86 platform.
Conclusions:
- Table 3 above uses TOPS claims on both sides. TOPS is a failed metric for real work. The metric is easy to calculate but significantly over-estimates the actual performance. Even with the complex Wikibon modifications, it is nowhere near giving a reliable idea of the performance of real-world applications.
- The Wikibon 50:1 ratio between Heterogeneous Compute and traditional should be taken with a grain of salt. However, this ratio is likely to be very high.
- A much better long-term metric and foundation for performance estimation are multiple benchmark figures for different Matrix Workloads.
- Matrix Workloads are very different and do not work well on traditional architectures. The Apple A13 Heterogeneous Compute architecture is a much better fit for these workloads, and the parallelism can be extended with multiple NPUs to address larger workloads.
- The future Apple A13X and A14 chips will have increased performance, increased power envelopes, and improved architectures.
- Apple/TSMC and Google/Samsung are investing heavily in Matrix consumer applications. The rate of innovation is high.
- Enterprise Matrix Workloads are unlikely to work well on GPUs or traditional x86 architectures. Arm-based solutions look set to be dominant in running Matrix workload in mobile, PCs, distributed servers, and datacenter solutions.
Footnote 3: The Facial-recognition Matrix Workload
This thought experiment workload is to design a facial recognition system that ensures six nines of confidence that nobody enters a highly secure facility who is not authorized to do so. There is a compliance requirement to have a specific record of who is or has been in the facility at any time. Thousands of people enter and leave the facility every day. There a limited number of entrance and exit points.
Everybody who is authorized to enter has a machine-readable card in their possession. The job of the system is to read the card, used infrared 3D light to scan the face, and compare the face as recorded in the entry system with the facial record held in the system. The only way a new record of a facial record can be entered into the system is by the person being physically present at the site with the card, with the necessary authorized paperwork. The facial data is entered into the system at this time.
To avoid potential misuse of facial data (e.g., to change a facial data record), the facial data can only be held at the site, and cannot be accessed by any other application, or read or written by any other device other than the facial recognition system. An immutable record of every access to the facial data must be held, but the facial data is not included in this record. In the case of any attempt to access this data, the facial data must self-destruct.
Clearly a manual system could not meet the 6 nines requirement. One assumption in this thought experiment is that Apple commercially offers the software to run the facial TruDepth recognition system.


