
Premise
Data scientists are rapidly adopting solutions for automating every step of the machine learning (ML) development pipeline. Developers have access to a growing range of tools for automating various stages of the ML pipeline. Available ML automation solutions include both commercial and open-source tools, and they come with varying degrees of integration in organizations’ existing DevOps environments.
Data science productivity is improving rapidly, enabling more work to be accomplished with fewer data scientists.
Developers have access to a growing range of tools for automating various phases and processes of the machine learning (ML) pipeline. Available solutions automatically sort through a huge range of alternatives relevant to ML development, optimization, deployment, and operationalization tasks. They help data scientists to assess the comparative impacts of design and administration options on ML model performance in real-world applications. And they recommend and execute the best alternatives so that data scientists can focus their efforts on those rather than waste their time exploring options that are unlikely to pan out.
Available ML automation solutions vary widely in the scope of pipeline phases and processes they address. A comprehensive solution would automate ML modeling, training, and refinement, as well as the front-end processes of data discovery, exploration, and preparation and the back-end and ongoing processes of ML deployment, operationalization, and governance. A growing range of these solutions leverage specialized ML algorithms to drive automated development, optimization, and deployment of ML models. This recent Wikibon note discusses the entire ML pipeline that may be automated with ay of the solutions discussed in this current study.
For ML development professionals, solutions include both commercial and open-source automation tools. Wikibon provides the following guidance for enterprises exploring available solutions automating their ML pipelines:
- Familiarize yourself with open-source ML modeling, training, and refinement toolkits
- Consider standardizing on full data science DevOps tools with strong ML modeling, training, and refinement automation features
- Stay aware of leading-edge ML automation approaches being developed by commercial and academic organizations
Familiarize yourself with open-source ML modeling, training, and refinement toolkits
Open-source ML automation tools typically address a subset of the core processes associated with modeling, training, and refinement. Most support ML programming in Python or R and come integrated with common ML libraries. Table 1 discusses open-source ML-automation tools.
| TOOL | DESCRIPTION |
| Scikit-learn | This tool automates algorithm selection and hyperparameter optimization. It comes with several different estimator functions for learning from provided data. |
| TPOT | This tool automates hyperparameter selection, algorithm selection, and feature engineering. It uses a scikit-learn pipeline. uses genetic programming, and produces ready-to-run, standalone Python code for the best-performing model. |
| Auto-Sklearn | This tool automates algorithm selection, hyperparameter tuning, and data preprocessing. It uses Bayesian optimization, meta-learning, and ensemble construction. It provides a drop-in replacement for a scikit-learn estimator to captures the probabilistic relationship between model settings and their performance. It uses a model’s Bayesian optimization features to select settings that trade off exploration of uncertain elements of candidate machine-learning model architectural space against exploitation of those parts of the space likely to perform well. |
| Machine-JS | This tool automates feature engineering and algorithm selection. It also advises the user as to whether their problem, given the amount of data available, is as yet solvable by ML. |
| Auto-Weka | This tool uses Bayesian optimization to automate algorithm selection and hyperparameter tuning. |
| Spearmint | This tool uses Bayesian optimization to automatically run experiments that iteratively adjusts model hyperparameters to achieve the ML model’s objectives in as few runs as possible. |
| Sequential Model-based Algorithm Configuration | This tool automates hyperparameter selection so that the models that scale more efficiently and effectively to higher dimensional feature spaces. |
Table 1: Open-Source ML-Automation Tools
Consider Standardizing On Full Data Science DevOps Tools With Strong ML Modeling, Training, And Refinement Automation Features
Several data-science DevOps tool vendors provide ML-pipeline automation features. Compared to the open-source toolkits discussed above, these commercial tools automate a broader range of ML pipeline processes. They focus on automating the modeling, training, and refinement of ML models, but also automate some front-end collaboration, exploration, and preparation as well as some back-end deployment, operationalization, and governance processes.
Chief among these commercial ML automation products are solutions from Alteryx, AWS, DataRobot, Domino Data Lab, PurePredictive, Tellmeplus, and Xpanse AI. The following discussion includes some of the solutions that we focused on in the Wikibon report on data science DevOps tool suites, but excludes the solutions in that report that don’t automate the core ML-pipeline processes of modeling, training, and refinement. Table 2 provides an overview of their support for the various ML automation pipeline processes.
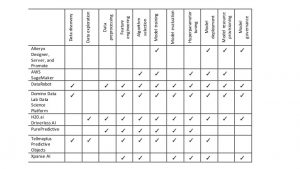
Table 2: Open-Source ML-Automation Tools
Alteryx
Alteryx’s product suite implements the following ML automation capabilities:
- Automated ML training: Alteryx Designer workflows can be set up to automatically retrain machine learning models, using fresh data, and then interface to Promote to automatically redeploy them.
- Automated ML deployment: The no-code Alteryx Designer tool automatically generates customized RESTAPIs and Docker images around machine learning models during the promotion and deployment stage. The Alteryx Promote tool automatically deploys the models for execution in the Alteryx Server analytics platform.
- Automated ML provisioning: Promote can automatically scale each model’s runtime resource consumption up or down based on changing application requirements.
- Automated ML governance: Alteryx Promote automatically ensures model governance by keeping track of which model version is currently deployed and making sure that there is always one sufficiently predictive model in production.
AWS
AWS’s Amazon SageMaker implements the following ML automation capabilities:
- Automated workflow: The solution incorporates built-in DevOps workflows. SageMaker provides a fully managed cloud service provides an abstraction layer for teams of data scientists and developers to collaborate on building and deployment sophisticated AI-driven apps.
- Automated model selection, training, hyperparameter optimization, and deployment: The solution enables developers to pull data from their S3 data lake, leverage a library of preoptimized algorithms, build and train models at scale, and optimize them through ML-driven hyperparameter optimization. SageMaker is configured for MXNet and TensorFlow. Amazon SageMaker automatically configures and optimizes TensorFlow and Apache MXNet, so customers don’t have to do any setup to start using these frameworks. However, customers can bring any framework to Amazon SageMaker by building the framework into a Docker container stored in the Amazon EC2 Container Registry. SageMaker is agnostic to the underlying development framework and runtime libraries that are used to build and train models. Developers access SageMaker through hosted Jupyter notebooks and can run with it with their choice of AI modeling frameworks (including MXNet, TensorFlow, CNTK, Caffe2, Theano, Torch or PyTorch).
- Automated deployment: The solution automates model deployment in real-time into production EC2 cloud instances
- Automated provisioning: The solution allows ML developers to take advantage of built-in autoscaling of their deployed models in EC2.
DataRobot
DataRobot’s flagship product implements the following ML automation capabilities:
- Development workflow: DataRobot automatically creates the predictive modeling and other ML development workflows. It knows what to do at each step of the process, and does it automatically, without prior programming or manual input from users. It enables business users to generate accurate models quickly and perform sophisticated data science functions directly.
- Data discovery: DataRobot automatically connects to data sources wherever they reside, including relational databases, Hadoop clusters, and text files.
- Data preprocessing: DataRobot prepares, cleanses, transforms, and reformats data automatically. It automates one-hot encoding, missing-data imputation, text mining, and standardization to transform features for optimal results.
- Feature engineering: DataRobot automates the boosting, bagging, and other feature engineering tasks. It automates detection of anomalies in datasets, using an unsupervised ensemble blend model. It automates classification on targets with up to 10 distinct values, offering both real-time and batch support for uncovering the predictive class and showing its probability across all classes.
- Algorithm selection and model training: DataRobot runs and trains dozens of different algorithms at once, ranking their performance. DataRobot uses open source machine learning libraries, including R, scikit-learn, TensorFlow, Vowpal Wabbit, Spark ML, and XGBoost. It automatically selects algorithms to be utilized, including Random Forests, Support Vector Machines, Gradient Boosted Trees, Elastic Nets, Extreme Gradient Boosting, and ensembles,
- Model evaluation: DataRobot runs and trains dozens of different algorithms at once, ranking their performance. It builds a leaderboard so that developers can see which models perform best with the data, and provides the tools they need to explore and compare individual models. Users can download DataRobot’s diagnostic charts, data, and documentation to share them with executives, stakeholders, and regulators. It provides customizable rating tables which allow users to edit and manipulate the tables to enable an optimal blend of machine learning and human judgement in the model evaluation workflow.
- Hyperparameter tuning: DataRobot automates model hyperparameter optimization, but also supports manual tuning so data scientists can adjust machine learning algorithms.
- Model deployment: DataRobot automates ML deployment to cloud and on-premises environments. It supports deployment to public clouds (AWS, Google Cloud, Microsoft Azure), the DataRobot Cloud (a SaaS offering powered by Amazon Web Services), to on-premises DataRobot Enterprise Hadoop platforms (Cloudera, Hortonworks), and to on-premises DataRobot Enterprise Linux platforms (Virtual Machines, Virtual Private Clouds). It supports model deployment via API or exports code in Python, C, or Java. Options for deploying finished ML models include native scoring, exportable prediction code, and prediction APIs for real-time and batch scoring.
- Model provisioning: DataRobot automates provisioning of distributed computing resources to run ML-based experiments in parallel. Its Resource Monitor provides a view of platform usage across the organization, including which workers and models are taking up runtime, enabling effective resource planning. It uses Hadoop distribution’s application management services to distribute runtime libraries to Hadoop Data nodes.
- Model governance: DataRobot enforces a consistent modeling workflow in the building, validating, optimizing, and deployment of ML models, including generalized linear models, deep learning, random forests, and kernel-based methods. It offers native security for fine-grained role-based authorization and supports Kerberos and LDAP protocols. In Hadoop, it works with existing encryption policies.
Domino Data Lab Data Science Platform
Domino Data Lab’s Data Science Platform implements the following ML automation capabilities:
- Development workflow: The solution automates ML development, deployment, and collaboration using customers’ existing tools and languages. It leverages popular data science tools, including database drivers, Anaconda Python, popular deep learning packages, and visualization packages. It accelerates iteration and experimentation among teams of data scientists, supporting single-click spin-up of interactive workspaces in Jupyter, RStudio, SAS, and Zeppelin. It enables flexible sharing and discussion of work among collaborators and stakeholders in one place.
- Data discovery: The solution automatically connects to any data including cloud databases and distributed systems such as Hadoop and Spark.
- Feature engineering, algorithm selection, model training, and hyperparameter tuning: When used with a third-party ML-automation workspace such as H20 Flow, the solution supports automation of feature engineering, algorithm selection, model training, and hyperparameter tuning.
- Model evaluation: The solution automatically runs, tracks, and compares batch experiments in parallel with any language, including commercial languages like SAS or Matlab. It supports scheduling of recurring tasks to update reports, so that results can be served through the web or sent to stakeholders via email. It supports access controls on dashboards and reports from Control access to dashboards and reports from a central security layer. It automatically publishes visualizations using open source data science tools, including knitr, Plotly, D3, etc. or for commercial tools like Tableau. It automatically publishes interactive dashboards and web apps using Shiny and Flask. It supports automated scheduling of update reports through the web or via email.
- Model deployment: The solution enables rapid publishing of visualizations, interactive dashboards, and web apps. It automatically deploys batch or real-time APIs of Python and R models.
- Model provisioning: The solution automates compute-grid environment management by leveraging scalable compute with powerful, centralized hardware in the cloud or on premise. It provides one-click access to GPU hardware. It reduces software configuration time by running code in Docker containers, configured to create shared, reusable, revisioned Compute Environments. It supports web-scale ML processes with automated horizontal scalability. It automatically splits traffic across versions to do A/B testing.
- Model governance: The solution automatically tracks code, data, results, environments and parameters in one central place. It controls access with granular permissions and LDAP integration.It automatically preserves all key project information with Domino’s containerization and dependency map, enabling teams to save data, software configurations, code, parameters, results, discussion, and delivered artifacts as they happen. It streamlines knowledge management with all projects stored, searchable, and forkable. It uses native integrations with popular source control systems such as GitHub. It automatically rolls back to prior versions of models. It automatically manages security for consuming and modifying production models. It automates identity management with integrations into LDAP. It manages hand-offs, sensitive information, and regulatory standards with integrated and granular user access management.
H2O.ai Driverless AI
H20.ai’s Driverless AI solution implements the following ML automation capabilities:
- Data exploration: The solution provides “Automatic Kaggle Grandmaster recipes in a box” for solving a wide variety of ML use cases. It incorporates an AI-driven expert system that mimics how Kaggle Grandmasters address ML problems.
- Data preprocessing: The solution leverages the data-preparation tools provided in the underlying H20.ai platform.
- Feature engineering, algorithm selection, model training, and hyperparameter tuning: The solution leverages the ML libraries and automated ML tools provided in the underlying H20.ai platform. On top of that, Driverless AI enables users to create and train high-quality ML for execution in Hadoop and Spark without needing any special expertise in ML development. Using web UI, developers can write Python client programs to access Driverless AI features. The tool’s default workspace automates ML development through the paradigm of “experiments.” The workspace allows users to pick training data sets, target columns, and the maximum number of rows for experiments. It enables users to choose one or more target variables in the dataset to solve for and then automatically generate an ML model that deliver the insight being sought. It supports automated feature engineering and annotation to increase accuracy and interpretability. Launching an experiment in the solution automatically starts the feature engineering process. The solution automatically trains and scores many models while applying transformations to the data fields to create new features with better predictive power between epochs. After evaluating all epochs, it runs a full training and prediction generation with the final feature set. H2O.ai’s underlying AutoML module focuses on hyperparameter tuning of the different algorithms and finding the best combination or ensemble for a problem. It enables manual adjustments to experiment settings, such as the target accuracy of the ML model to be generated, the number of training epochs to run, the ensemble level, how many cross-validation folds to use in each model, whether to perform feature selection permutations.
- Model evaluation: The solution automates the delivery of visual model interpretations. It presents model explanation and results via interactive charts, and explains them with plain-English annotations and reason codes. It supports interpretability for model debugging. It leverages K-Lime, LOCO, partial dependence and other advanced approaches for generating global and local explanations that increase the transparency of the ML model. It allows model behavior to be validated and debugged by analyzing the provided plots, comparing global and local explanations to each other, to known standards, to domain knowledge, and to reasonable expectations. It provides a rollup of model interpretations, including a global interpretable model explanation plot, a variable importance bar chart, a decision tree surrogate model, and partial dependence and individual conditional expectation plots.
- Model deployment and provisioning: The solution automatically runs ML pipeline tasks on multiple GPUs and/or CPUs. It leverages multi-GPU acceleration to achieve up to 40x speedups of XGBoost, GLM, Kmeans and other algorithms. It can run thousands of iterations that drive utilization to achieve best performance. And it is fully integrated on NVIDIA DGX systems, enabling users to apply automatic feature engineering and quickly develop hundreds of machine learning models that have been optimized for NVIDIA DGX systems.
- Model governance: The solution leverages the model repository in the underlying H20.ai platform.
PurePredictive
PurePredictive’s flagship solution implements the following ML automation capabilities:
- Data preprocessing: The solution automatically performs cleansing, missing imputation, and transformation of data sets.
- Feature engineering: The solution automatically discovers important features and interactions in the data.
- Algorithm selection: The solution automates selection of ML algorithms to be used in the model. It simultaneously runs thousands of variations on ML algorithms (regression, classification, decision trees, neural nets, SVMs, BDMs, etc.).
- Model training: The solution automatically trains ensembled model variations from the training data.
- Model evaluation: The solution automatically evaluates ensembles consisting of thousands of candidate models to produce highly accurate champion models
- Hyperparameter tuning: The solution produces ensembles that consist of model variations that were generated from application of various hyperparameter setting on various ML algorithms.
Tellmeplus
Tellmeplus’ Predictive Objects solution implements the following ML automation capabilities:
- Data exploration, data discovery, and algorithm selection: The solution automatically searches for the best combination of algorithms and data sets.
- Feature engineering, model training, model evaluation, and hyperparameter tuning: The solution automatically generates all suitable candidate model in the domain defined by user-specified goals, training and evaluating each to ensure that the best combination of algorithm and data is always selected.
- Model deployment: The solution automates delivery of auto-generated models that can be manually enriched and operationalized by domain specialists, based on their expert human judgment of whether the models are fit for production deployment.
Xpanse AI
Xpanse AI’s flagship solution implements the following ML automation capabilities:
- Feature engineering: The solution automatically creates and test hundreds of thousands of features from relational data, tailored specifically to the problem being modelling. It delivers a flat modelling table, ready to use in the user’s favorite ML algorithms or tools.
- Algorithm selection: The solution automatically chooses the most appropriate ML algorithms for the modeling problem.
- Hyperparameter tuning: The solution automatically chooses the most appropriate ML hyper parameter configurations for the modeling problem.
- Model evaluation: The solution automatically uses advanced validation techniques to avoid model overfitting. It automatically outputs the auto-generated model’s performance charts and metrics. It automatically explains – both graphically and in plain English – how all the features built for the modeling program correlate with a target variable, helping to understand the drivers of the model and to explain the model to the business.
- Model deployment: The solution automatically outputs a highly tuned predictive model.
- Model governance: The solution automatically outputs all transformations as well as the predictive model scoring code in ANSI SQL, ready to be deployed to any relational or other database of the user’s choice.
Stay Aware Of Leading-Edge ML Automation Approaches Being Developed By Commercial And Academic Organizations
Leading commercial organizations (e.g., Google), nonprofit research institutes (e.g., OpenAI), and universities (e.g, MIT, University of California Berkeley) have their smartest computer scientists working on ML automation. Consequently, there are myriad specialized ML automation projects under development in the research community– such as object recognition–with which the more adventurous developers may wish to familiarize themselves. Many of these incorporate advances in transfer learning and other sophisticated AI techniques to enable reuse of ML artifacts across projects. Here are some of the noteworthy ML-automation projects underway in the commercial and academic worlds.
Google AutoML
Google’s AutoML project iteratively refines deep learning architectures. It develops, trains, and refines multilayered neural-net architectures in repeated iterative rounds. It automates feature engineering, algorithm selection, model training, model evaluation, and hyperparameter optimization in successive runs.
To drive these iterative refinements, AutoML relies on Bayesian, evolutionary, regression, meta-learning, transfer learning, combinatorial optimization, and reinforcement learning algorithms. It uses a “controller” neural net to propose an initial “child” neural-net architecture that it trains on a specific validation data set.
AutoML may take hundreds or thousands of iterated rounds for the controller to learn which aspects of the neural-net architectural space achieve high vs. low accuracy with respect to the assigned learning task on the training set. AutoML’s controller node acquires feedback from the performance of the child model, with respect to a particular learning task, for guidance in generating a new child neural net to test in the next round.
Auto Tune Models
Auto Tune Models automates feature engineering, algorithm selection, model training, model evaluation, and hyperparameter optimization. Developed by researchers at the Massachusetts Institute of Technology (MIT) and Michigan State University (MSU), it uses a cloud-based, on-demand computing to search for the best possible modeling technique for a given problem.
Auto Tune Models automatically build and evaluates thousands of ML models in parallel, evaluating each, and allocating more computational resources to the ones that best fit the problem. It automatically adjusts model hyperparameters to gain the best results. As discussed here, in laboratory tests, it took Auto Tune Models less than a day to create a model that performed better than one that took human data scientists an average of 200 days to create. It displays evaluations as a distribution, enabling researchers can compare different models’ performance.
Auto Tune Models is available for enterprises as an open source platform. It can run on a single machine, local computing clusters, or on-demand clusters in the cloud, and can work with multiple datasets and multiple users at the same time.
IBM Cognito
IBM’s Cognito project automates feature engineering. Its technique, Learning Feature Engineering (LFE), automates feature engineering in classification tasks. It automatically learns which transformations are effective on a feature in the context of a given problem. It does this by examining thousands of predictive learning problems and making associations between the effectiveness of a transformation in specific situations. And, when a new problem is presented, it instantly comes up with the most effective feature choices, based on its experience. It doesn’t rely on model evaluation or explicit feature expansion and selection. Using datasets, it leverages a low-computational-cost neural network approach that predicts the transformation that impacts classification performance positively.
Action Item
Wikibon recommends that developers explore the productivity potential of commercial and open-source ML automation tools. Give preference to comprehensive solutions from such vendors as DataRobot, Domino Data Lab, and H20.ai, which automate most preparation, modeling, and operationalization process in the ML pipeline.


