Executive Summary
The overall Worldwide Big Data market for products and services is in the midst of explosive growth, topping $27 billion in 2014, growing to over $61B by2020 – a compound annual growth rate of 15%. Professional services represented 43% of the market in 2014 and its use is widespread. According to Wikibon’s Big Data Analytics Adoption Survey 2014, 72% of U.S. Big Data practitioners leverage professional services to assist in deployments.
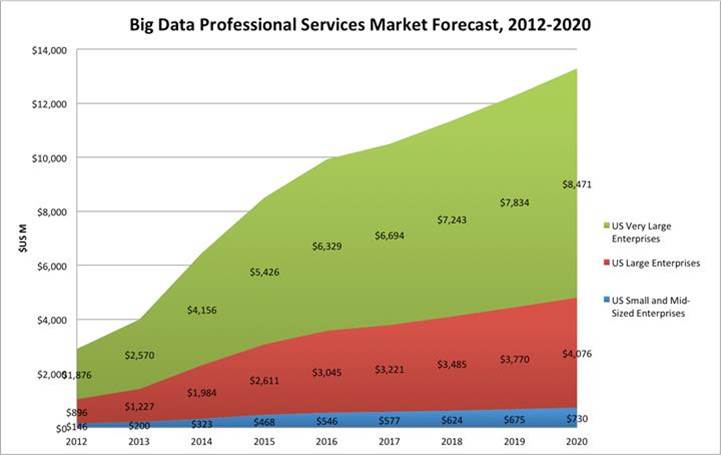
Big data Professional Services will grow from $6.46 billion in 2014 growing to $13.3 in 2020 (Figure 1). From a vertical market perspective Financial Services/Banking was the largest vertical market reaching $1.9 billion in 2014 and growing at 16% annually. Retail, and Telecomm are also leading vertical industry growth segments. The Global 1000 is the leading consumer of U.S. Big Data Professional Services (64%).
Figure 1: US Big Data Professional Services Forecast 2012-2020
Wikibon believes there is significant opportunity for Big Data professional services companies as the market shifts from early adopter status to early majority status. Large enterprises that will make up the early majority adopters lack many of the skills required to support Big Data deployments, but recognize the importance of leveraging data-driven insights to remain competitive.
Professional services in the context of Big Data includes systems integration services, consulting services, application design and deployment services, application management services, analytics and data science services, and training & education. Professional services is in high demand due in part to the complexity involved in architecting, deploying and maintaining Big Data analytics software and hardware, as well as the advanced skills required to derive insights from Big Data and to operationalize said insights.
Big Data Adoption Factors and Professional Services
Big Data adoption is currently concentrated in two parts of the market (Figure 2). On one end of the “barbell” are data-driven emerging enterprises (such as Uber, Netflix, and AirBnB). These companies are born as data-driven enterprises and, as such, Big Data is core to their competitive differentiation. By definition, emerging enterprises have little to no legacy infrastructure to contend with and are starting with a blank slate, making the adoption of Big Data technology relatively frictionless. As such, they made be less in need of third party professional services since their emerging businesses have it built into their DNA.
Figure 2: Profile of US Big Data Professional Services Adoption by Enterprise Size

On the other end of the barbell are Very Large Enterprises in the Global 1000. These enterprises recognize the necessity of becoming more data driven and are investing heavily in related Big Data technologies and services. Large Enterprises – the global 3000 – are also beginning to invest in Big Data products and services, but not to the same levels as very large enterprises. In between the two ends of the barbell are Small and Medium sized Enterprises where there is very little investment in Big Data technologies and services today.
When it comes to decision processes and drivers impacting the decision to engage with Professional Services, these four groups can be differentiated on the following:
Very Large Enterprises (Global 1000)
- Complex, interesting data and business transformation challenges
- Many have budget, motivation, vision, willingness for risk, skills
- Long decision and implementation cycles (12 to 18 months)
- Eventually want to bring Big Data & Data Science expertise in-house
Large Enterprises (Global 3000)
- Interesting, but less complex data and business challenges
- Shorter decision and implementation cycles
- Require infrastructure (ETL, data pipelines), data governance as well as Data Science help
- Motivated to get value from recent Big Data investments.
Small and Mid-Sized Enterprises
- Very little investment in Big Data technology or services
- Little to no budget, motivation, vision, willingness for risk, etc.
- Little ability to leverage Big Data or Data Science output
- Focused on short-term nuts and bolts/just starting in busines.
Emerging Enterprises
- Many have Big Data built into their DNA
- No legacy technology to deal with
- Ready and motivated to leverage Big Data
- Will have relatively high skill levels in place today or will ultimately want to bring expertise in-house
Early Adopters Are Driving the Market
While the value of Big Data is clearly considerable and potentially disruptive to the normal course of business, Big Data (unlike many other IT projects) is inherently risky with hard-to-quantify payback. Early Adopters can be characterized as having:
- The budget to fund Big Data projects
- The vision to understand how Big Data will impact their organizations and their industries
- The motivation to embark on Big Data projects in the face of uncertain results
- The willingness to take risks and the perseverance to follow‐through;
- The ability to operationalize results of Big Data projects and take action based on Big Data insights
Companies that are likely to being in the lead deploying Big Data solutions include:
- Global 2000 and other large enterprises with over $1 billion in annual revenue
- Enterprises struggling with traditional data management costs associated with data storage, processing and analytics
- Enterprises with mature data warehouse practices and an established data-driven culture
- Enterprises that have dabbled with Big Data technology but have yet to realize full value
- Information‐intensive service providers, especially in banking and finance, and retailers with large volumes of customers (and hence large volumes of customer data)
U.S. Big Data Professional Services Market Forecast 2014-2020
Because the Big Data market is still emerging, Wikibon focused its attention to the U.S. (as the leading region where the technology is unfolding) and on three leading vertical markets – Financial Services/Banking, Retail, and Telecommunications. “Other” is still the largest segment overall, but these three verticals represented key targets for Big Data today. We have also observed that enterprise size matters a great deal to patterns of adoption.
The U.S. Big Data professional services market was $6.46 billion in 2014 growing to $13.3 billion in 2020 (Figure 1). From a vertical market perspective (Figure 3), Financial Services/Banking was the largest vertical market reaching $1.9 billion in 2014 and growing at 16% annually to $2.6 billion in 2020. Retail will grow from $679 million to 1.9 billion in that period (18% CAGR). Telecommunications was $169 million in 2014 and will grow to $1 billion in 2020 (22% CAGR).
Very Large Enterprises had 64% of the spending ($4.16 billion), Large Enterprises $1.98 billion (31%), and Small-Medium Enterprises (SMEs) just $323 million, or 5% of the market. The Very Large Enterprise segment of the U.S. Big Data professional services market will grow to nearly $8.5 billion by 2020 (a CAGR of nearly 13%). Large Enterprises will experience a CAGR of 13%, topping $4 billion in 2020. The SME segment will grow more rapidly at 15% annually, reaching $730 million in 2020.
Figure 3 shows the breakdown of the U.S. Big Data professional services market by vertical and by company size/type.
Figure 3: US Big Data Professional Services Market 2012-2020 by Vertical Market

Vertical Market Big Data Use Cases
Wikibon interviewed nine Big Data practitioners in Financial Services/Banking, Retail, and Telecommunications. Based on these conversations and related research, Wikibon has identified both vertical-specific Big Data use cases as well as universal use cases applicable across verticals. While Big Data practitioners may be looking at scores of cross-industry and industry-specific application possibilities, these stood out as having the most interest and largest payoffs today. Other industries will have unique use cases as well that are not covered within the scope of this report.
Universal Big Data Use Cases
- Data Warehouse Optimization: Leveraging Hadoop to offload historical data and appropriate workloads from existing relational data warehouse systems in order to reduce costs.
- Data Lake/Large-Scale ETL: Building off Data Warehouse Optimization, using Hadoop as the foundation of a large-scale data staging and analytics environment, including large-scale data transformations to support both existing and new analytics use-cases.
- IT Operations Optimization: The use of big data for IT systems operations monitoring and diagnosis is an important Big Data use case across all industries.
Financial Services & Banking Big Data Use Cases
- Customer Analytics: Bringing together disparate customer data currently siloed across divisions (retail banking, mortgage lending, equities trading, etc.) to gain a single-view of customer and conducting analytics to identify upsell and cross‐sell opportunities.
- Fraud Detection: Identifying patterns in large volumes of financial transaction data, potentially blended with other data sources, to identify and stop fraudulent activity.
- Compliance: Leveraging Big Data technologies to comply with existing and emerging regulations in both the U.S. and Europe that require financial services firms and banks to track and report financial trading activity and proactively identify potentially fraudulent or illegal activity.
Retail Big Data Use Cases
- Analytics: Like financial services, bringing together all customer data from various sources – transactional data, social media data, location data, etc. – to gain a comprehensive view of the customer, performing customer segmentation and analytics to understand buying patterns and drivers, and identifying upsell and cross-sell opportunities.
- Price Optimization: Analyzing customer transaction data, competitive pricing data and other relevant data sources to identify optimal pricing for products and services to further specific business goals (i.e. maximize profit, increase market-share, drive higher customer loyalty, etc.)
- Supply Chain Optimization and Inventory Management: Leveraging analytics against supplier data, inventory data, customer buying behavior data and other data sources to identify optimal inventory levels across product categories with the aim of minimizing excess inventory and reducing operation costs.
Telecommunications Big Data Use Cases
- Customer Analytics: Analyzing customer usage data to identify most valuable customers, determine upsell and cross-‐sell opportunities, identify and reduce customer churn and to improve overall customer service to maximize customer retention.
- Network Optimization: Monitoring network traffic to identify bottlenecks and other performance degradation, performing large-scale analysis of data and traffic flows to identify more efficient ways of moving data across the network with the aim of improving overall performance and meet SLA requirements.
Competitive Landscape – Pure Play Vendors
The market for U.S. Big Data professional services is crowded with competitors including the “usual suspects” for any leading edge initiative – the large consulting firms (Accenture, Deloitte, Cap Gemini, IBM GBS, etc.) where the Big Data offering is likely to be embedded within vertical or general analytics practices. To tease out the nature of Big Data (in itself) professional services practices, Wikibon elected to characterize Big Data professional services providers by focusing on pure play Big Data providers (and one BI generalist). There are scores of these in the U.S. market, but we chose 5 to interview specifically and briefly sketch as examples.
Clarity Solutions
- Building from its general analytics/data warehousing skills.
- Big data is emerging skill set.
- Dedicated analytics/data warehousing US firm with 300 practitioners with $50M in revenues, and growing at ~20%/year.
- Probably 100 similar companies with data warehouse, BI focus in the US.
Cloudwick
- Focusing on Big Data horizontal stacks and partnering with vertical industry experts to deliver Big Data solutions.
- Provides Data Science and application development services, but does not believe it is possible to be expert in both infrastructure and apps.
- It has well over 100 data architects, scientists, and engineers primarily in North America with approximately $20‐$25m in annual revenue. They extended their reach to Europe and Asia-Pacific in 2014.
Silicon Valley Data Science
- Leadership is Big Data “intellectual horsepower” and reputation is their strength.
- Marketing is key – exposure of all their Big Data talent via publishing, presentations at shows, etc.
- See lots of outsourced engineering from SW providers. Try to leverage experiences into new assignments. In early 2015, Wikibon estimates that Silicon Valley Data Science had ~35 employees and annual revenue of $10$15m.
Think Big (Teradata)
- Offers “end-to-end” Big Data service in five phases: roadmap, data lake creation, prototype application & visualization, production, ongoing managed services.
- Typical teams are 4 to 7 consultants with some on‐site, some off‐site.
- At time of acquisition by Teradata (September 2014), estimated headcount 70, mostly technical, with estimated $15m annual revenue.
Zaloni
- Started out as pure professional services focusing on data ingestion, which they were finding to be a big problem.
- Built software to complement its services offerings.
- Software sits on top of Hadoop – manages data transfers, metadata, etc.
- Product is 90% complementary to Hadoop so they can still partner with Hortonworks, Cloudera and not be seen as competition.
- As of early 2015, approximately 150 employees and $25-$30m in annual revenue.
Advice: Big Data Professional Services Critical Success Factors
Big Data professional services are an integral part of the journey to deploying applications that leverage the learnings and models that Big Data enables. Professional Services firms (as well as decision makers and users) should consider the following as they engage in Big Data projects and evolve their practices – or in the case of users their Big Data analytic strategy.
- In the current environment, building the data lake, establishing ETL at scale & speed, and ensuring proper data governance are all significant bottlenecks for many Big Data early adopters and soon-to-be early mainstream adopters.
- Many of these early Big Data projects in the enterprise are IT‐led and often result in failure. Successful projects address a business challenge/opportunity while simultaneously laying a strong Big Data foundation that can be leveraged for future use cases.
- Users are also struggling to apply Big Data analytics (i.e. the results of data science) to operational, real‐time systems and event-driven automation (i.e. for scoring for next best offer, churn risk actions, etc.). Build expertise in real-time ETL and integration of OLTP and OLAP to enable in-line analytics.
- Very Large and Large enterprises in the banking, retail and telecommunications markets are the leading adopters. They need services for both data infrastructure and data science.
- Identify and execute against business-led use cases, including net-new customer-focused marketing and sales Big Data use cases that can stand separately from the data warehouse and can return immediate reward.
- Automate data integration and data transformation workflows, i.e., building a “re-useable” Big Data foundation (a.k.a. Data Lake) that can be applied across vertical/horizontal use cases and “get you 60%-70% of the way there.”
Appendix A – US Big Data Professional Services Market Forecast 2012-2020 Data Table

Appendix B – Big Data Project and Outcomes Profiles
Wikibon conducted 9 interviews with Big Data practitioners at various stages of adoption for this study. The profiles highlight the Big Data drivers, usage, and experiences of a broad set of Banking/Finance, Retail, and Telecomm users. For each, we characterized:
- Current Big Data Status
- Business Problem
- Project Team
- Solutions Implemented
- Project Cost/Manpower
- Length of the Project
- Value Received
- Criteria for Success
These profiles illustrate that there is a significant breadth of problems, solutions, tools, and goals for Big Data projects that users are embracing.
Very Large Telecommunications Provider
Big Data Status – Many internal and external applications.
Business problem– Internal reports characterizing customer usage, churn, network performance SLAs, etc. Also building a data business selling phone contact information to industry to help them determine the source of calls (at the exchange level) of competitor contacts to help them determine generally who (companies, not individuals) their competition is contacting. Also, the US government requires they share this sort of metadata with it for national security reasons. They also use the data to create more competitive and profitable product offerings tailored to customer segmentations. They use this data to tune and tailor their network, i.e. where to place cell towers and radios and correctly size and scope them to meet the demands of a particular geographic area. Also, service providers like Netflix want this sort of data for its own target marketing and customer usage and segment analysis.
Project team – These sorts of Big Data applications have been long term businesses and have dedicated Ph.D. data science teams for delivering data of different sorts – internal and external. They also do a lot of their own training and education programs in this area. Due to the sensitivity of this sort of data, they do not generally depend on professional services to help them build out the apps. When they need assistance, they operate under strict rules of disclosure and security with well-known providers.
Solution implemented ‐ Long-term organizational teams. Their phone call database of all calls made ‐ the calling number, the called number, duration of call, addresses, names, call duration, holds, etc. is one of the largest databases of its type in the world. A financial services company, for instance, can see where its competitors’ phone traffic is coming from to a high degree of granularity, i.e., definitive area code and local exchanges. This sort of competitor network analysis can be very valuable for a company. They use SAS for many of their analytics applications with this data.
Length of the project – Ongoing.
Value Received – Company delivers higher SLAs to its network customers, complies with regulatory requirements from the US government for disclosure for national security, and enables them to build a data delivery business for commercial customers. Service reliability is a very important factor that they devote a lot of resources to.
Criteria Defining Success – Increased profitability from better service delivery and creation and sale of data products to commercial customers.
Luxury Retailer (<$1B in sales) with Multiple Brands and both Storefront and Web-based Channels
Big Data Status – They have purchased Hadoop software and are loading up their database and expect to have it usable in about 2 months.
Business problem– They mine a customer database for grouping classification, shopping trends and bits and facts about their market segments. Every touch point is gathered including in-store identity management, kiosks, POS, tracking identity from its tracking cameras. Email, click through rates, online cookied activity data, everything is captured. Their philosophy is to capture all the omni-channel data and then figure out what they can use it for at a later time. They have eight distinct shopper segments they track and do micro-marketing to. They also track the type of products that are successful and not successful and focus on selling the good products at full price as early in the season as possible. The more they can maximize full price selling, the more important it is for them to identify the products early on to market, because they know the hot products will go if people know they’re there.
Project team – They have an in-house data services team of data specialists working the data side of the project. They see the task as not being very complicated, but time consuming since they are going back 3 years for history. The marketing team is going to expand their reporting to cover all the new data sources. They expect they will have to engage with some Data Scientists to fully exploit this new capability once they get the data where they want it.
They regard themselves as an agile shop and develop their own software. They use third parties like ThoughtWorks, IBM, Sapient, and Nitro to support their older monolithic applications and to educate and find the best practices and development models or new techniques.
Solution implemented – They have Teradata for their user segmentation work. They’re moving over to Hadoop with SAS for clickstream (Facebook, Twitter, etc.) analysis to do unified collection of all the marketing efforts throughout all their channels and tied it into the store data. The data warehouse they’re setting up is marking reputation information from social media sites, knowledge of the product through emails and texts, etc.
They are starting off with a 25 TB data warehouse, but expect to expand it to 200TBs. The long range goal is to replace the outsourcing of clickstream data and bring it in house and unify it with other customer data in a data warehouse. They bought an Oracle Data Appliance and a SAS front end that matches up to their current toolset and are now loading the data in. Starting small, they will be able to show the proof of concept that they can save marketing costs by hyper-segmenting. Their goal is to unite the many internal and external (Adobe Omniture) data sources into one data warehouse concept. After they get that up and operating, a second major goal will be to determine what new reports and views of the data they should be using to optimize sales and inventory.
Project cost – Purchasing an Oracle Data Appliance and SAS. Internal data specialists and marketing analytics and reporting staff are on the project.
Length of the project – Expect the database will take two months to load up on Hadoop. Then they will start analytics.
Value Received – They hyper-segment so their marketing department can send out tactical emails for sales to just those likely to buy certain types of products and save on having to blast out a sale to everyone in their database. Also, they have plugged store inventory into the website to improve store and ecommerce sales to better coordinate where the inventory is, where the purchase was made, and how they actually got the product to the customer.
Criteria Defining Success‐ At this proof of concept stage, they are trying to reduce marketing costs by hyper-segmentation. Additional goals are the ability to maximize timely sales early in the season to realize full pricing and manage inventory to the demand is one measure. Also, they are trying to reduce the delivery time to the customer as well as managing inventory at the store level. At this point they are operating on faith that this will be worthwhile. Ultimately this project will be an ongoing process that will continually be improved and adjusted to maximize the outputs.
ILEC – Former Bell Telephone Regional Operator (>1M Residents)
Big Data Status – Exploration. They have significant legacy data integration problems to overcome but have explored how Big Data could help them in that process and how analytics would make them more competitive.
Business problem– They are looking at Big Data so they can have a holistic view of their business – from their own physical infrastructure to the status of their customers and prospects so they can better create and support new product offerings for their customer base. They have a significant challenge competing with a much larger nationwide cable operator with the scale and capital to create new products in their territory. Also, the most significant barrier today is the multiple legacy systems (customer data, billing data, GIS, marketing data, operational data, physical asset data) that make normalizing business and operations data very difficult to use across the company. Big data is potentially a path to resolve this and get the benefits of analytics. ETL and data governance are significant issues for them. Among the possible big data apps they are considering include
- Customer churn analysis ‐ essentially BI in a box with a dashboard for all their order customer order activity, i.e., what they are buying, what are they actually paying, what’s the net margin on the service, what’s the gross margin on the service, and when do you have disconnects, do you have activations, do you have upgrades, downgrades, side grades, etc. Perhaps as many as 15 major performance metrics we need to analyze and deal with.
- Operational considerations -‐ what speeds can we connect a customer to, what plant is available to maximize the connection speeds to a customer, and what is the cost profile of getting the maximum speed available to the customer.
Project team – The respondent is a Sr. Manager of the software support and development group. They originally had a BI team to develop better data management and analytics. But after 3 years, their management didn’t see enough progress. Accenture does most of their development and data integration work today and is a contender for doing the overall Big Data project. They have been working some of the data integration problems that will enable this user to get closer to actually deploying some Big Data solutions.
Solution implemented ‐ They have gotten quotes from IBM and Accenture for essentially “BI in a box”. Accenture has helped them unravel some of their data integration issues, but there is much more to do. They believe the complexity of their situation and the special requirements of telecoms require a significantly experienced partner. They are not seriously considering anyone else.
Project cost -‐ Assume $3M over 3 years if they go forward with IBM or Accenture to attack Big Data and related data integration problems.
Length of the project – Because of legacy system integration requirement, they see the Big Data project running for multiple years.
Criteria Defining Success– They expect that the project would enable them to accurately see their assets and customers in a way that they could now plan, launch, and market product offerings that would make them more competitive with their primary competitor. Absent this knowledge, it will be very hard for them to plan and deliver new products. Creating new revenue will be the measure of the success of the project.
Large Mutual Fund and Financial Services Company
Big Data status – He described Big Data as being still in its infancy. While they regard themselves as an advanced technology consumer, they did not have an overall Big Data strategy or any central Big Data assets to share. This was in part because they are a very decentralized company and each business unit has a significant degree of autonomy. So, the Big Data activity was being run by the individual application and business groups.
Business problem– He identified 3 general use cases:
- Customer-facing: Most of the activity going on appeared to be in the customer- facing area. Their Marketing and Product groups were deploying customer- facing Big Data applications like“ next-best offer” and getting a holistic view of the customer. For instance, they were looking at the status of all of an individual client’s accounts (i.e. 401K and separate brokerage accounts) in order to analyze how they are trading and how each portfolio related to the other. This would enable them to identify individual investment choices (mix of investments across all accounts) that might point to where a client may need some investment education.
- Risk Management: They used Big Data to analyze network security threats and attacks. This was a key area for them, as well.
- Internal staff network analysis: They were experimenting with enabling existing internal staff relationships and assets (IM dialogues with peers, SharePoint information, prior work roles, organizational history and experiences, other metadata) to be known so one worker could know more about what other staff in the company were doing in the way of addressing issues or working on similar projects – now or in the past. As a result they could draw on existing (or potential) internal corporate knowledge more efficiently, enabling better levels of collaboration and information sharing.
Value Received – He was not aware of any specific Big Data professional services being purchased by any of the groups. He noted that, in general, ~80% of their development work is internally generated.
Investment Subsidiary of Large Global Bank
Big Data status – They sell financial instruments and investment vehicles for their customers. They also have a leasing business. Just starting out in Big Data. Their use is heavily integrated into their sales and marketing process.
Business problem– They get a lot of customer and prospect queries about investment options that may or may not be a good fit for the products they offer. They meld customer data (investment profile and goals, type of investments they are interested in, etc.) with their own offerings and related market data to modify their standard products so that they will better fit the prospect’s goals. The goal is to deliver the proposal very rapidly (within 3 days) and have it better fit the prospect’s requirements.
Project team – This is being implemented internally with MongoDB which they see as much better than relational models. This is a corporate‐wide effort involving 60-70 staff people ‐ business people, analytics, developers, database, and network etc. – basically the entire company. They had some initial consulting help, but they decided to start slow and then build their internal staff knowledge and skill to handle more of the problem, which they see (at least so far) as a data management vs. an analytics challenge. They didn’t hire any new staff. They regard their team as being very of experienced and capable, and they knew what they needed to learn, so they feel they can do it themselves – and they could afford it vs. going with professional services firms that they see as expensive. But they do acknowledge that it’s still early days in the Big Data process.
Solution implemented ‐ MongoDB “gave us very quick ways to collect, analyze load, and get the data to our research and analytics department so that they can come out with product ideas”. They compared the pricing and the support of MongoDB vs. a few competitors and decided they were very competitive. The MongoDB support office was close to their location, which they found very helpful in rapidly solving some problems in person.
They have a lot of data feeds including market data, social media, history, their own product data (25 or 26 parameters), etc. They continually improve their algorithms and applications to improve upon what they are doing. They are incorporating competitor information into their system as well so they can demonstrate their value against them and how the company’s product is better than the others.
Project cost – Internal effort.
Length of the project – 3 months from start to deliver a customer information application. They have 2-3 other projects underway to expand their Big Data capabilities.
Value Received – They get ~30% of their prospects (100s a day) to call back about their proposals – much higher than their response rate before they developed the system.
Criteria Defining Success– Time to market with an offer to a customer request for a proposal. Their target is to get an offer back to a customer within 3 days of the initial sales call. They have been evaluating their progress for the past 6 months and regard the results so far as very positive. They see themselves as just at the beginning, but the business people have been very enthusiastic because they can communicate substantive offers back to prospects very rapidly. “The Big Data effort will not change every aspect of how we do business, but some things will definitely change because we are only a couple of months in production and we have seen the advantage of the Big Data databases. But it’s definitely going to change the strategy of our company.”
Financial Information Services Business ($2-$3B Annually)
Big Data Status – Their major lines of business are handling middle and back office functions and regulatory compliance for bank broker/dealers and investor communications. Moving from successful prototype demonstration built by Think Big to incorporating Big Data tools and concepts into production applications.
Business problem– Between their lines of business, they have a significant amount of data they can mine to look for process improvements and the ability to monetize the data significantly. Also, is important to them to establish a uniform enterprise platform as they potentially get rid of their legacy RDBMS structures (i.e., mainframes, AS/400s) and move to NoSQL, but with full transactional support.
Solution implemented ‐ Started by bringing in companies like Think Big about 1.5 years ago at the recommendation of someone on their IT team. “We also were looking at products like Hadoop, Cassandra, MongoDB, MarkLogic, VoltDB and others. Think Big basically took our requirements and put them up against all the different vendors. Then they showed how the data could be rapidly monetized. After that, they did a few workshops with the investor communications team and the IT group to demonstrate how to set up the cluster, brought the product vendors in, and did a set of presentations for the executive management team. The Think Big project showed how Big Data worked as a CRM tool, which they really were not interest in. But it gave them an idea of how Big Data solutions could be built and which software vendors they should consider.
After this engagement, the company set up a few proofs of concept themselves to see how each database tool handled their expected Big Data report writing workloads. The company took the concepts to the next level and was able to demonstrate a huge increase in interactive report creation (minutes vs. hours) speed. So they are moving to a production environment for the solution. They intend to find an appropriate SI with banking industry expertise and 1 or 2 business savvy data scientists as a next step to get this into production. They hadn’t yet found an SI to work with, but mentioned EPAM (an SI with Big Data knowledge) as a possibility. They are concerned about a lack of depth in Big Data service offerings generally.
Project cost – Not revealed. The respondent made a comment “people will get into Big Data whether they’re a small bank, medium bank or a big bank. The amount of money will end up surprising them. The entry point looks and smells real cheap, but the lack of skills will escalate the costs.”
Length of the project – The company built the above robust prototype in 2 months. The overall project is still in production development mode and is progressing slowly, but steadily.
Value Received‐ In the end, they expect that the rapid reports will improve their process and customer visibility and improve operations.
Criteria Defining Success–They thought the Think Big portion of the project was very successful as an education of their staff by introducing Big Data concepts and tools. But they feel companies like Think Big fall down when it comes down to delivering something beyond that.
Online Store Analytics for Very Large Global Retailer
Big Data Status – Many projects deployed and underway.
Business problem – Rapid online store customer analytics.
Project team ‐They have multiple internal teams working on multiple projects all the time. They hired the Big Data talent they needed since it is becoming a core competency. One consideration vs. professional services is that you need the flexibility to act quickly when it comes to understanding the data itself and understanding the company’s strategies going forward. Having in house expertise lends itself to being very flexible. They decided to take the time to bring the expertise in-‐house and then train up their existing staff on the necessary tools.
Solution implemented ‐ This large retailer uses everything – Hadoop, Platfora, Tableau, SAS, R, Spark, Microstrategy, Teradata and MySQL, and many others. They are transitioning from a relational model to a Big Data model. Need Hadoop because of the size of customer transaction files. They did not consider Big Data professional services firms.
Project cost – Significant, ongoing investments.
Length of the project – Multiple ongoing.
Value Received – The first benefit was IT cost reduction -‐ migrating from a relational to a Big Data platform.
Criteria Defining Success‐ “At the end of the day we sell widgets. So when we look at it, the question is: what is going to give us a better advantage when we sell these widgets? Everything revolves around that. So anything that we can bring up that says, “Hey, this is going to help us understand this better, faster, more efficiently”.
“At the end of the day if you’re looking at supply chain or if you’re looking at your retention rate, or make corrections to processes, or whatever, everyone in the company wants to see specific views that are expressed in different algorithms or models that they’ve built. You want them to be able to tune them themselves”
When asked about start‐up sorts of engagements, this company had no need for them. But when asked about a “Jump Start” sort of product (short engagement to validate the value and easy deployability of a Hadoop cluster), for smaller retailers, this respondent thought they might have some use. He saw their problem as one of having to do something now to improve their customer and sales-related processes with some better analytics. He thought they would be less likely to have a grand strategy, but would rather focus on getting better answers than what they have today.
“But more importantly, there are thousands of people here who want to see how their process, product, location, P&L, etc. is performing hour-to-hour and how to improve it. It’s no different than sitting at a cash register and checking these sales every hour. Couple that information with the type of people that are walking in, what’s the weather like, precisely what region are we talking about. It’s all potentially important for improving our business.”
“Once we perfect upselling, inventory management, etc. with real time Big Data results, it will have a major impact on sales. Being able to have product managers and literally anyone with a need to know being able to generate the exact report they need (and actions to take) at that time is the goal.”
Heavy Equipment Dealership ($800M Annual Sales)
Big Data Status –Their Big Data program was deployed by their manufacturer, but the dealer uses a lot of the data from the reports that are generated. They are looking at how to integrate the report data into their own data warehouse.
Business problem– Manufacturer pays for the Big Data gathering and analytic process. The dealer uses some of the data – how they compare to other dealers in terms of pricing, product models sold, seasonality trends, etc. Also, it’s useful operationally for supply chain, failure analysis, replacement parts inventory forecasting, warranty, competitor equipment dealer sales, etc.
Project team – Unclear as most of the Big Data heavy lifting is done by the parent manufacturer.
Solution implemented – The manufacturer is working with IBM and SAP to create the data warehouse and analytics and data framework. ETL had been a major challenge in the past. A key value-added the manufacturer provides is that they normalize all the data between dealerships so they can compare themselves accurately. Hadoop is the main platform. The manufacturer has created an internal website for the dealer’s user staff to access. The dealers themselves don’t have near the budget or skills to try to do anything like this themselves. So what they get from the manufacturer’s system meets all their current need for this type of information. They do, however, have the capability of incorporating some of their CRM system information analysis into the data outputs from the manufacturer. At the dealer level they are building analysis services on top of an SQL Server Enterprise 2012 so they can better manipulate and use the data that is provided. They also use an industry-specific analytics firm for doing a similar type of dealer‐to‐dealer comparison for their leasing business. The most important factor in choosing an IT solutions partner is that they know their specific business (heavy equipment sales) very well.
Length of the project – Years and continually improving capability and insights.
Value Received – “Sales, parts, service, and management all use these reports to gauge how we’re doing relative to our peers and for ideas about how to do things better or what to expect next.”
Criteria Defining Success– They didn’t pay for it, but the outputs from the Big Data analytics system of the manufacturer have improved their knowledge of their own business and has allowed them to plan better. But they don’t have specific metrics about the impact of big data.
Small Bank Payments System Service Provider
Big Data Status – They are in operation with their Big Data program – basically its embedded in their current operations and they are looking for new ways to exploit it for their customers.
Business problem – They are a cloud payments processing firm that needed Cassandra because of the unique requirements of their business. They generate some customer experience analytics for their use.
Project team – All in-house. Big Data is integral to their entire business model, so many people are involved from business side to IT. The team implementing the project is two IT staff.
Solution implemented -They got a lot of help from DataStax in the beginning regarding how to map their schemas. Since then they are using a tool whereby the developers can probe at the data and write their own queries. Originally, they bo ught a support contract and had the architects get them up and going. The support contract was really important in the event that something went wrong. But now that they have the experience and confidence in what they are doing, so they don’t buy support anymore.
They looked at RavenDB, MongoDB, and Cassandra and decided on Cassandra because it accommodated really wide rows, which they needed. Their architecture is all event-driven. They operate in the cloud, using OpenStack in Rackspace. They’re an agile shop, so they do deployments every two weeks. They’ve gone from future requests to production in three weeks as opposed to 2 or 3 a year like their competition.
When they start something new, they may bring in external services or send staff for training. But, it’s important for them to be as self-sufficient as possible – especially since they tear down their databases every few weeks.
Project cost – 2 internal staff people.
Length of the project – They are still working on the core application, but went from prototype to production in about three months. A lot of the work involved their user interface. They can bring up a brand new environment in a matter of a command and do a deployment at will with no downtime to the user. This flexibility is vital to their success.
Value Received – They get more banks as customers since they can help the banks customers to reduce their costs. Banks have to provide bill pay because it makes them stickier with their customers. Bank customers are less likely to leave a bank because they’re paying their bills out of it and it would be a pain to set that up somewhere else.
This company does some basic analytics like load graphs to understand how many resources they need to allocate. They also know how the user is interacting with their site (# of clicks to execute a payment) so they can improve user experience and their interface design.
They offer a predictive model about what kinds of bills that consumers have, i.e., when they make recurring payments, so that banks can sign them up for recurring payments if the consumer doesn’t actually have that service. They can also point to payments made by the bank’s customers to another bank for other services – so that their banking customer can offer their financial product instead. But their typical customer isn’t set up to use that sort of data yet.
Criteria Defining Success‐ They are growing very rapidly, so their method of providing bill paying services is obviously very appealing to their customers. There are other possibilities to extend their services in other directions, but they’re just focused for now in building our customer base.

