At our inaugural Supercloud22 event we sought community input to evolve the concept of a supercloud by iterating on the definition, the salient attributes and examples of what is and is not a supercloud. We asked several technologists including experts from VMware, Snowflake, Databricks, HashiCorp, Confluent, Intuit, Cohesity and others to help test the supercloud definition, operational models, service models and principles.
In this Breaking Analysis we unpack our discussions with these technology leaders and apply their input to iterate the definition of supercloud. We then go in-depth to examine Snowflake’s Data Cloud architecture as a leading example of supercloud.
Defining Supercloud
With the input of the community, we made an attempt below to simplify and make more clear the definition of supercloud.

Supercloud is an emerging computing architecture that comprises a set of services which are abstracted from the underlying primitives of hyperscale clouds. We’re talking about services such as compute, storage, networking, security & other native tooling like machine learning and developer tools, to create a global system that spans more than one cloud.
We’ve identified five essential properties of supercloud and at least three deployment models. We continue to seek input and clarity on the service models and input on the definition overall.
The Five Essential Characteristics of a Supercloud
Below, we lay out the essential characteristics, which taken together comprise supercloud.

First a supercloud has to run its services on more than one cloud…leveraging the cloud native tools offered by each of the cloud providers. The builder of a supercloud platform is responsible for optimizing the underlying primitives of each cloud and optimizing for their specific needs – be it cost or performance, latency, governance, data sharing, security, etc.
Those primitives must be abstracted such that a common experience is delivered across the clouds for both users and developers.
The supercloud has metadata intelligence that can maximize efficiency for the specific purpose the supercloud is intended for and does so in a federated model.
Supercloud includes what we’ve previously called a superPaaS that is purpose built and enables a common experience across clouds for users and developers. Matt Langguth (@gsxesx) suggests perhaps a better label would be “cloud interpreter.” This capability is built to support applications & services spanning more than one CSP such that they appear as a single system; created using programming languages, libraries, services, and tools supported by the provider.
Three Deployment Models Identified at Supercloud22
In terms of deployment models, we’d like to get more feedback on this section but several technologists weighed in at this week’s event. We asked Kit Colbert of VMware to present his point of view on what an initial architecture for supercloud might look like. [Note: VMware doesn’t use the term supercloud in its marketing, rather they talk about multi-cloud services]. Colbert summarized his thoughts in a recent paper entitled The Era of Multi-Cloud Services has Arrived and made the following two points:
- Abstraction alone does not solve the challenge of building, managing, governing and optimizing applications and workloads across multiple clouds.
- A multicloud service must provide a consistent API, object model, identity management along with other functions.
In the paper, and in expanded commentary on theCUBE, Colbert identified the following characteristics of a multi-cloud service:
- Runs on a single cloud but supports interactions with at least two different clouds. One example he used was a cost optimization service. Another was a Kubernetes cluster management service with a control plane only on AWS but can deploy and managed clusters on other clouds or at the edge.
- Runs on multiple clouds and supports interactions with at least two different clouds – i.e. the solution is instantiated on multiple clouds.
- Runs on any cloud or edge, even in disconnected mode and basic operations are fully automated.
We further tested these characteristics to try and hone in on specific supercloud deployment models. Colbert’s work and discussions with technologists including Snowflake’s Benoit Dageville and Cohesity’s Mohit Aron, HashiCorp’s David McJannet and Confluent’s Will LaForest led us to land on the following:

We see three supercloud deployment models emerging:
- One where a control plane may run on one cloud but supports data plane interactions with more than one other cloud.
- The second model instantiates the supercloud services on each individual cloud and within regions and can support interactions across more than one cloud with a unified interface connecting those instances to create a common experience. In discussions with Mohit Aron, we believe this is the approach Cohesity takes.
- And the third model superimposes its services as a layer on top of the cloud providers’ regions with a single global instantiation of those services; and the services span multiple cloud providers. This is our understanding as to how Snowflake approaches the solution based on our discussions with Benoit Dageville.
For now we’re going to park the service models – we need more time to flesh that out and will propose something soon on which people in the community can comment.
Another takeaway from Supercloud22 is that there are standard infrastructure services that are well understood and can be used to build capabilities across clouds. Companies like HashiCorp and Confluent are not building superclouds, for example, but they are building cross-cloud capabilities on which superclouds can be built.
[Listen to HashiCorp CEO David McJannet explain his pragmatic view of supercloud services].
Examining Snowflake as a Supercloud Example
Snowflake doesn’t use the term Supercloud, rather they use the phrase Data Cloud to describe what we feel is a supercloud. Snowflake and other partners of AWS, Azure and GCP don’t want to overly promote the fact that they’re using hyperscaler CAPEX as a building block because one could infer from that positioning that the public cloud becomes a commodity layer.
Our view is: 1) This approach consumes a lot of public cloud services; and 2) The hyperscalers aren’t standing still and we never say never when it comes to their next moves. But the commoditization of hyperscalers is a topic for another day.
We tested several questions with Snowflake’s co-founder and President of Products, Benoit Dageville. Let’s roll through them to evaluate the ‘supercloud-ness’ of Snowflake’s Data Cloud.
How Does Snowflake Architect the Data Cloud?

Dageville stated the following:
There are several ways to do this supercloud, as you name them. The way we picked is to create one single system, and that’s very important. There are several ways. You can instantiate your solution in every region of the cloud and potentially that region could be AWS, that region could be GCP. So, you are, indeed, a multi-cloud solution. But Snowflake, we did it differently.
We are really creating cloud regions, which are superimposed on top of the cloud provider region, infrastructure region. So, we are building our regions. But where it’s very different is that each region of Snowflake is not one instantiation of our service. Our service is global, by nature. We can move data from one region to the other. When you land in Snowflake, you land into one region. But you can grow from there and you can exist in multiple clouds at the same time. And that’s very important, right? It’s not different instantiation of a system, it’s one single instantiation which covers many cloud regions and many cloud provider.
[Listen to Benoit Dageville discuss Snowflake’s architectural approach to the Data Cloud].
It appears Snowflake chose the third deployment model of the three we cited above, presumably so it could maintain maximum control and ensure a common experience. But are there tradeoffs? We examine this later in the discussion.
What are the Technical Enablers of Data Cloud?

According to Dageville:
As I said, first we start by building Snowflake regions. Today we have 30 regions that span the world, so it’s a world wide system, with many regions. But all these regions are connected together. They are meshed together with our technology, we named it Snowgrid, and that is technically hard because Azure region can talk to an AWS region, or GCP regions, and as a user of our cloud, you don’t see these regional differences and that regions are in different clouds. When you use Snowflake, you can exist, your presence as an organization can be in several regions, several clouds, if you want. Both geographic and cloud provider.
We asked Dageville: “Can I share data irrespective of the cloud I’m in? In other words I’m in the Snowflake cloud…what we call the super data cloud. Is that correct? Can I do this today?
Dageville’s response:
Exactly, and that’s very critical, right? What we wanted is to remove data silos. And when you instantiate a system in one single region, and that system is locked in that region, you cannot communicate with other parts of the world, you are locking data in one region. And we didn’t want to do that. We wanted data to be distributed the way customers want it to be distributed across the world. And potentially sharing data at world scale.
[Listen to Benoit Dageville discuss Snowflake’s Snowgrid mesh approach].
Now he uses the term mesh and this can get confusing with Zhamak Dehghani’s data mesh concept but in studying the principles of data mesh and interviewing Zhamak Dehghani several times we do see Snowflake’s Data Cloud following data mesh principles pretty closely. With the possible exception that Deghani’s data mesh dreams materialize via sets of open standards. We’ll come back to that later in this post.
As well, there are many ways to solve technical challenges, meaning perhaps if a platform does instantiate in multiple places (e.g. how we understand Cohesity) there are ways to share data; but this is how Snowflake chose to approach the problem.
How Does Snowflake’s Data Cloud Handle Latency Challenges?

The next obvious question is what about latency. We asked Dageville: “Does that mean if I’m in one region and I want to run a query…say for example if I’m in AWS in one region and I want to run a query on data that happens to be in an Azure cloud thousands of miles away, I can actually execute that?”
Here’s what he said:
So, yes and no. It is very expensive to do that. Because, generally, if you want to join data which are in different regions and different clouds, it’s going to be very expensive because you need to move data every time you join it. So, the way we do it is that you replicate the subset of data that you want to access from one region from other region. So, you can create this data mesh, but data is replicated to make it very cheap and very performing too.
We then asked: “And Snowgrid has the metadata intelligence to actually manage that?
Dageville responded:
Yes, Snowgrid enables the capability to exchange metadata. So, each region of Snowflake knows about all the other regions of Snowflake. Every time we create a new region, the metadata is distributed over our data cloud, not only region knows all the region, but knows every organization that exists in our cloud, where this organization is, where data can be replicated by this organization. And then, of course, it’s also used as a way to exchange data, right? So, you can exchange data by scale of data size. And I was just receiving an email from one of our customers who moved more than four petabytes of data, cross region, cross cloud providers in, you know, few days. And it’s a lot of data, so it takes some time to move. But they were able to do that online, completely online, and switch over to the other region, which is very important also.
[Listen to Benoit Dageville discuss Snowflake handles latency across its global network].
So ‘yes and no’ probably means no in most cases. It sounds like Snowflake is selectively pulling small amounts of data and replicating it. But you also heard Benoit talk about the metadata layer which is one of the essential aspects of Supercloud. We always get nervous when we talk about moving lots of data across physical distances as it’s not an ideal use of resources; although sometimes it’s required.
On this topic we like to paraphrase Einstein…move as much data as needed but no more.
Security is Perhaps the Biggest Supercloud Challenge

In our securing the supercloud panel with Gee Rittenhouse, Tony Kueh and Piyush Sharma, it became clear that security is one of the biggest hurdles for supercloud.
We’ve talked about how the cloud has become the first line of defense for the CISO but now with multi-cloud you have multiple first lines of defense and that means multiple shared responsibility models and multiple tool sets from different cloud providers…and an expanded threat surface. Here’s Benoit’s explanation on how Snowflake deals with security in its Data Cloud.
This is a great question. Security has always been the most important aspect of Snowflake since day one. This is the question that every customer of ours has. You know, how can you guarantee the security of my data? And, so, we secure data really tightly in region. We have several layers of security. It starts by securing all data at rest. And that’s very important. A lot of customers are not doing that, right? You hear of these attacks, for example, on cloud, where someone left their buckets open. And then anyone can access the data because it’s not encrypted. So, we are encrypting everything at rest. We are encrypting everything in transit. So, a region is very secure. Now, you know, from one region, you never access data from another region in Snowflake. That’s why, also, we replicate data. Now the replication of that data across region, or the metadata, for that matter, is really the most vulnerable. So Snowgrid ensures that everything is encrypted, everything. We have multiple encryption keys, and it’s stored in hardware secure modules, so, we built Snowgrid such that it’s secure and it allows very secure movement of data.
[Listen to Benoit Dageville discuss Snowflake handles security in its Data Cloud].
What About the Lowest Common Denominator Problem?

When we heard the previous explanation we immediately went to the lowest common denominator question. For example, what if the way AWS deals with data in motion or data at rest it might be different from another cloud provider. So how does Snowflake address differences in the maturity of various cloud capabilities? What about performance, for example taking advantage of silicon advances from one cloud provider that is ahead of another. Does it slow everything down like a caravan so everyone can keep up?
Here’s what Dageville said:
Of course, our software is abstracting all the cloud providers’ infrastructure so that when you run in one region, let’s say AWS, or Azure, it doesn’t make any difference, as far as the applications are concerned. And this abstraction, of course, is a lot of work. I mean, really, a lot of work. Because it needs to be secure, it needs to be performant, for every cloud, and it has to expose APIs which are uniform.
And, you know, cloud providers, even though they have potentially the same concept, let’s say block storage, APIs are completely different. The way these systems are secured, it’s completely different. There are errors that you can get. And the retry mechanism is very different from one cloud to the other. The performance is also different. We discovered this when we started to port our software. And we had to completely rethink how to leverage block storage in one cloud versus another cloud, for performance and other reasons too. And, so, we had, for example, to stripe data. So, all this work is work that you don’t need as an application because our vision, really, is that applications, which are running in our data cloud, can be abstracted for this difference. And we provide all the services, all the workload that this application needs. Whether it’s transactional access to data, analytical access to data, managing logs, managing metrics, all of this is abstracted too, so that they are not tied to one particular service of one cloud. And distributing this application across many region, many cloud, is very seamless.
Ok so this was revealing and confirms one of our fundamental assertions that supercloud is actually a thing that requires new thinking and a novel architectural approach. This is not in what people think of as multi-cloud in our view. Search definitions of multi-cloud and we don’t think what you get represents what Snowflake is doing. And Snowflake’s choice of the phrase Data Cloud differentiates it from multi-cloud. Because as we’ve said many times, multi-cloud is really a symptom of multi-vendor and / or M&A.
Now from Benoit’s answer, we know Snowflake takes care of everything but we don’t really understand the performance implications.. We do feel pretty certain that Snowflake’s promises of governed and secure data sharing will be kept and are enhanced by its single global system approach. But what’s the advantage of running in multiple cloud providers? Is there a technical advantage – for example leveraging more regions and specific cloud provider capabilities; or is it really about TAM expansion?
In our clouderati influencer panel, Adrian Cockcroft, former CTO at Netflix put forth the counter argument that if you just build on one cloud it simplifies things and you can move faster. He gave the example of Liberty Mutual. But he also said that the developers are going to choose the best, regardless of where it lives. And the ops don’t like lock in so heterogenous clouds is probably the norm going forward.
[Listen to Adrian Cockcroft explain the one cloud may be better case].
SuperPaaS and the Cloud Interpreter

Another criterion that we’ve proposed for supercloud is a superPaaS layer to create a common developer experience and an enable ecosystem partners to monetize their services on top of a supercloud. Matt Langguth (@gsxesx) as we cited earlier suggests calling this the “cloud interpreter.”
We asked Dageville, did you build a custom PaaS layer or just use off-the-shelf tooling. Here’s how he explains Snowflake’s approach:
No, it is a custom build. Because, as you said, what exists in one cloud might not exist in another cloud provider. So, we have to build in all these components that a modern data application needs. And that goes to machine learning, as I said, transactional analytical system, and the entire thing. So that it can run in isolation physically.
We followed up with: “And the objective is the developer experience will be identical across those clouds?”
Yes, the developers don’t need to worry about the cloud provider.
Dageville did reference ecosystem but we’re not going to explore that in detail today. …we’ve talked about Snowflake’s strengths in this regard in previous episodes. But from our vantage point, Snowflake ticks many if not all the boxes on our supercloud attributes list.
Can Snowflake Deliver These Capabilities Today?

We asked Benoit Dageville to confirm that this is all shipping and available today – and he also gave us a glimpse of the future. Here’s what he said:
Yes, and we are still developing it. You know, transactional, Unistore, as we call it, was announced last summit. So, it is still work in progress. But that’s our vision, right? And that’s important, because we talk about the infrastructure. You mention a lot about storage and compute. But it’s not only that. When you think about applications, they need to use the transactional database. They need to use an analytical system. They need to use machine learning. So, you need to provide all these services which are consistent across all the cloud providers.
[Listen to Benoit Dageville discuss the future of Snowflake’s Data Cloud].
You can hear Dageville talking about expanding beyond taking advantage of core infrastructure and bringing intelligence to the data…so of course there’s more to come…there’d better be at Snowflake’s valuation…despite the recent sharp pullback in a tightening fed environment.
How Snowflake and Databricks Take Different Approaches
It’s popular to compare Snowflake and Databricks, we get it. Databricks has been pretty vocal about its open source posture compared to Snowflake’s and it just so happens that we had Ali Ghodsi on the program at Supercloud22. He wasn’t in the studio because he’s presenting at an investor conference.
John Furrier conducted the interview and we captured this comment from Ali Ghodsi on the importance of open source:
Let me start by saying, we’re big fans of open source. We think that open source is a force in software. That’s going to continue for, decades, hundreds of years, and it’s going to slowly replace all proprietary code in its way. We saw that, it could do that with the most advanced technology. Windows, you know proprietary operating system, very complicated, got replaced with Linux. So open source can pretty much do anything. And what we’re seeing with the Delta Lakehouse is that slowly the open source community is building a replacement for the proprietary data warehouse, Delta Lake, machine learning, real time stack in open source. And we’re excited to be part of it. For us, Delta Lake is a very important project that really helps you standardize how you layout your data in the cloud. And when it comes a really important protocol called Delta Sharing, that enables you in, an open way actually for the first time ever, to share large data sets between organizations, but it uses an open protocol.
So the great thing about that is you don’t need to be a Databricks customer. You don’t need to even like Databricks, you just need to use this open source project and you can now securely share data sets between organizations across clouds. And it actually does so really efficiently with just one copy of the data. So you don’t have to copy it if you’re within the same cloud.
[Listen to Ali Ghodsi discuss open source and its backing of Delta Sharing].
Obviously there’s a lot in this statement. The implication of Ghodsi’s comments is that Databricks, with Delta Sharing, as John implied, is playing a long game. And he’s essentially saying that over the course of time, anything that can be done with proprietary systems will be done in open source. And the comments about not having to copy data are intriguing but nuanced – i.e. within the same cloud. So it’s not clear if Databricks is building a supercloud – more discussion and research is required to determine if it has the elements that we’ve defined. Or perhaps Databricks has found a new way to achieve the same objectives. We’ll keep digging into it and as always will keep an open mind and invite community input.
But on this specific topic, to get more perspective, we reached out to two analyst friend of theCUBE, Tony Baer and Sanjeev Mohan.
Here’s what Tony said:
I’ve viewed the divergent lakehouse strategies of Databricks and Snowflake in the context of their roots. Prior to Delta Lake, Databricks’ prime focus was the compute, not the storage layer, and more specifically, they were a compute engine, not a database. Snowflake approached from the opposite end of the pool, as they originally fit the mold of the classic database company rather than a specific compute engine per se. The lakehouse pushes both companies outside their original comfort zones – Databricks to storage, Snowflake to compute engine.
So it makes perfect sense for Databricks to embrace the open source narrative at the storage layer, and for Snowflake to continue its walled garden approach. But in the long run, their strategies are already overlapping. Databricks is not a 100% open-source company. Its practitioner experience has always been proprietary and now, so is its SQL query engine. Likewise, Snowflake has had to “open up” with support of Iceberg for open data lake format. The question really becomes how serious Snowflake will be in making Iceberg a first class citizen in its environment that it is not necessarily officially branding a lakehouse, but effectively is. And likewise, can Databricks deliver the service levels associated with walled gardens through a more brute force approach that relies heavily on the query engine. At the end of the day, those are the key requirements that will matter to Databricks and Snowflake customers.
Sanjeev Mohan added the following:
Open source is a slippery slope. People buy mobile phones based on open-source Android, but it is not fully open. Similarly, Databricks’ Delta Lake was not originally fully open source, and even today its Photon execution engine is not. We are always going to live in a hybrid world.
Snowflake and Databricks will support whatever model works best for them and the customers. The big question is, do customers care as deeply about which vendor has a higher degree of openness as we technology people do? I believe customers’ evaluation criteria is far more nuanced than just to decipher each vendor’s open-source claims.
Why did Snowflake Introduce Support for Apache Iceberg?
We had to ask Dageville about their so-called walled garden approach and what Snowflake’s strategy is with Apache Iceberg. His comments are summarized below:
Iceberg is very important. So, just to give some context, Iceberg is an open table format. It was first developed by Netflix. And Netflix put it open source in the Apache community. So, we embraced that open source standard because it’s widely used by many companies. And, also, many companies have really invested a lot of effort in building big data, Hadoop solutions, or data lake solutions and they want to use Snowflake. And they couldn’t really use Snowflake, because all their data were in open formats. So, we are embracing Iceberg to help these companies move to the cloud. But why we have been reluctant with direct access to data, direct access to data is a little bit of a problem for us. And the reason is when you direct access to data, now you have direct access to storage.
Now you have to understand, for example, the specificity of one cloud versus the other. So, as soon as you start to have direct access to data, you lose your cloud agnostic layer. You don’t access data with API. When you have direct access to data, it’s very hard to sync your data. Because you need to grant access, direct access to tools which are not protected. And you see a lot of hacking of data because of that. So, direct access to data is not serving our customers well. And that’s why we have been reluctant to do that. Because it is not cloud agnostic. You have to code that, you need a lot of intelligence, we want open APIs. That’s the way we embrace openness, is by open API versus you access, directly, data.
[Listen to Beniot Dageville discuss the future of Snowflake’s Data Cloud].
Here’s our take. Snowflake is hedging its bets because enough people care about open source that Snowflake has to include some open data format options. And you heard Benoit Dageville talk about the risks of directly accessing the data and the complexities it brings. Is that maybe a little FUD against Databricks or other approaches? Perhaps. But same can be said for Databricks’ FUDing the proprietary-ness of Snowflake.
As both Tony Baer and Sanjeev Mohan point out, the open question lives on a spectrum. We remember the days when Unix was the example of open.
What the ETR Spending Data Tells us About Snowflake & Databricks
Comparing Snowflake & Databricks Spending Momentum
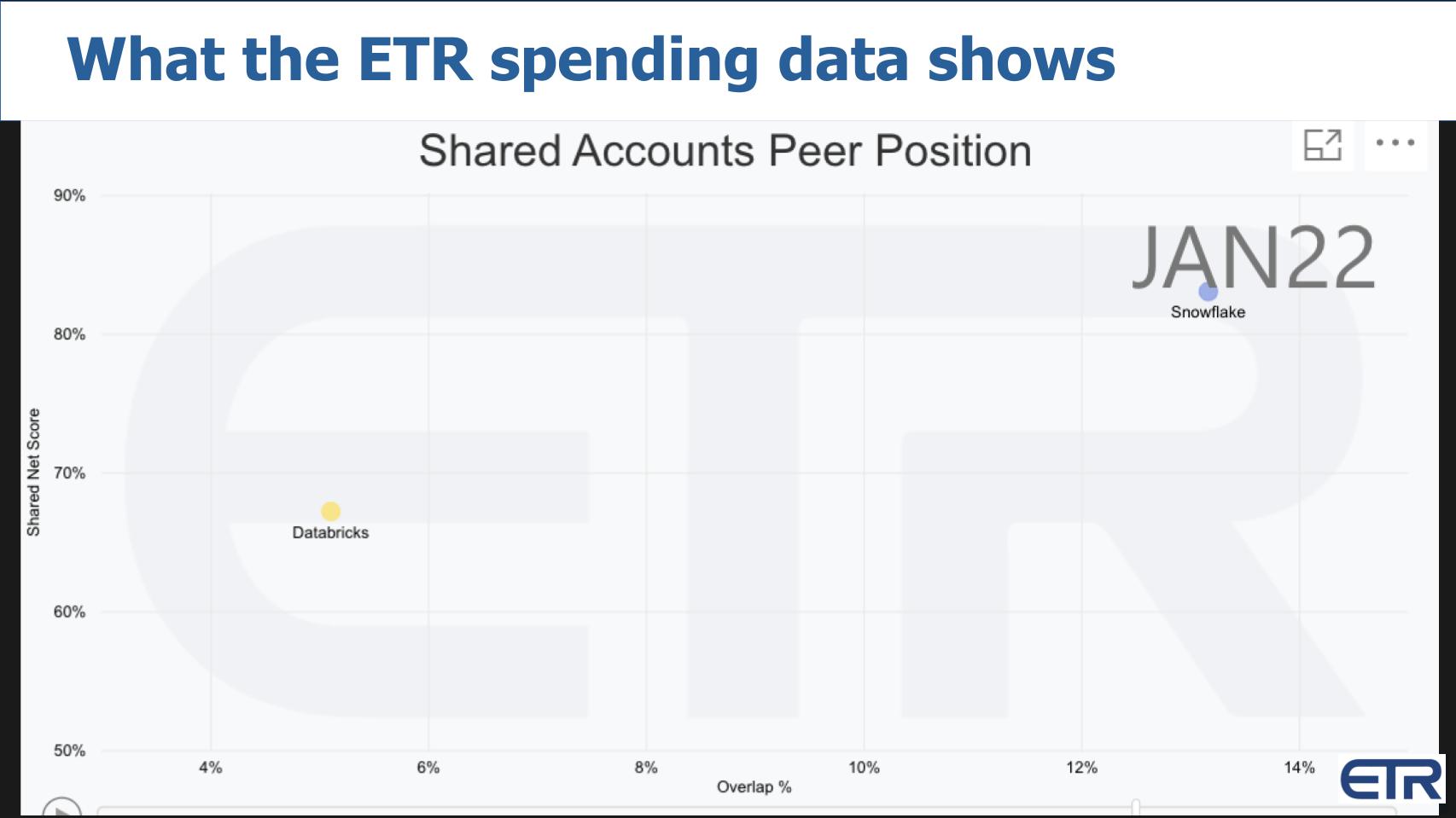
Above we show an XY graph with Net Score or spending momentum on the Y axis and pervasiveness or overlap in the dataset on the X axis. This is data from the January survey when Snowflake was holding above 80% Net Score. Databricks was also very strong in the upper 60’s.
Spending Momentum has Tempered for Both Companies but Especially for Snowflake
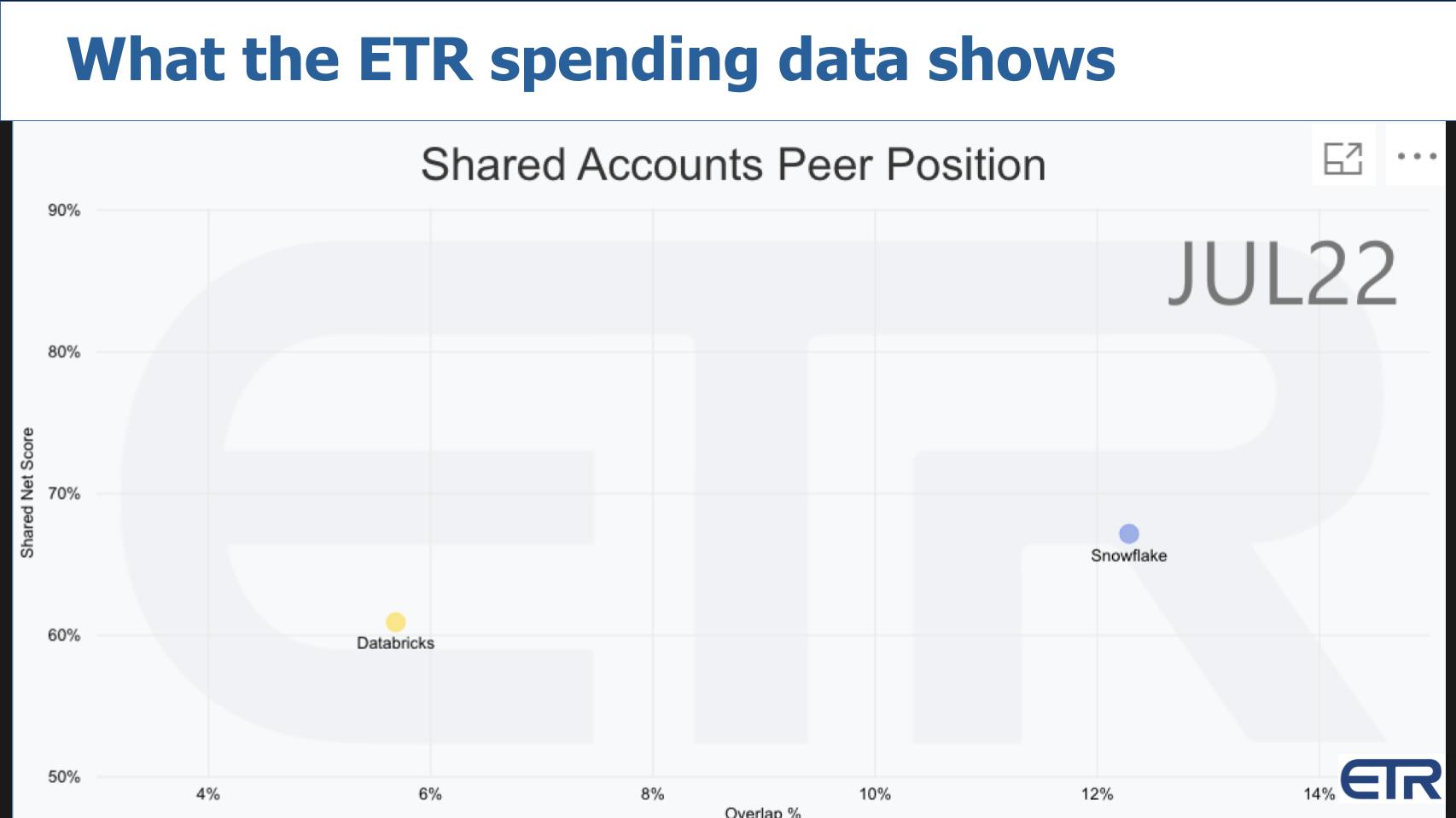
Fast forward to the July ETR Survey and you can see Snowflake has come back down to earth.
Remember – anything above a 40% Net Score is highly elevated so both companies are doing well. But Snowflake is well off its highs…and Databricks has come down some as well. Databricks is inching to the right as a private company. In the data, Snowflake rocketed to the right post IPO as we’ve reported.
As we know, Databricks wasn’t able to get to IPO during the COVID bubble. Ali Ghodsi spoke at the Morgan Stanley CEO conference last week. The company claims to have plenty of cash but they are starting to message that they have $1B in annualized revenue and we’ve seen some numbers on their gross margins and snapshots of NRR…but we’ll reserve judgment until we see an S1.
Nonetheless, it’s clear both of these companies have momentum and they’re out competing hard for business. The market, as always, will decide. Different philosophies? Perhaps. Is it like Democrats and Republicans? Well…could be. But they’re both going after solving data problems…both companies are trying to help customers get more value out of their data. And both companies are highly valued so they have to perform for their investors.
To quote Ralph Nader – the similarities may be greater than the differences.
Keep in touch
Thanks to Alex Myerson who does the production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.


