Data mesh is a new way of thinking about how to use data to create organizational value. Leading edge practitioners are beginning to implement data mesh in earnest. Importantly, data mesh is not a single tool or a rigid reference architecture. Rather it’s an architectural and organizational model that is designed to address the shortcomings of decades of data challenges and failures. As importantly, it’s a new way to think about how to leverage and share data at scale across an organization and ecosystems. Data mesh in our view will become the defining paradigm for the next generation of data excellence.
In this Breaking Analysis we welcome the founder and creator of data mesh, author, thought leader, technologist Zhamak Dehghani, who will help us better understand some of core principles of data mesh and the future of decentralized data management. With practical advice for data pros who want to create the next generation of data-driven organizations.
Discussion Focus

First, Zhamak Dehghani is the Director of Emerging Technologies at Thoughtworks North America. She is a thought leader, practitioner, software engineer and architect with a passion for decentralized technology solutions and data architectures.
Since we last had her on as a guest less than a year ago, she’s written two books – one on Data Mesh and another called Software Architecture: The Hard Parts…both published by O’Reilly
We’re going to set the stage by sharing some ETR data on the spending profile in some of the key data sectors.
We’ll then dive in and review the four key principles of data mesh and talk a bit more about some of the dependencies in the data flows. And we’ll really dig into principle #3 a bit around self service data platforms.
To that end, we’ll talk about some of the learnings Zhamak has captured since she embarked on the data mesh journey with her colleagues and clients. And we specifically want to talk about successful models for building the data mesh experience.
We’ll then hit on some practical advice and we’ll wrap with some thought exercises and common community questions.
Data-related Themes Top the Spending Charts
The first thing we want to introduce is the spending climate on some data sectors and their adjacencies. We’ll use the XY chart below to do so.
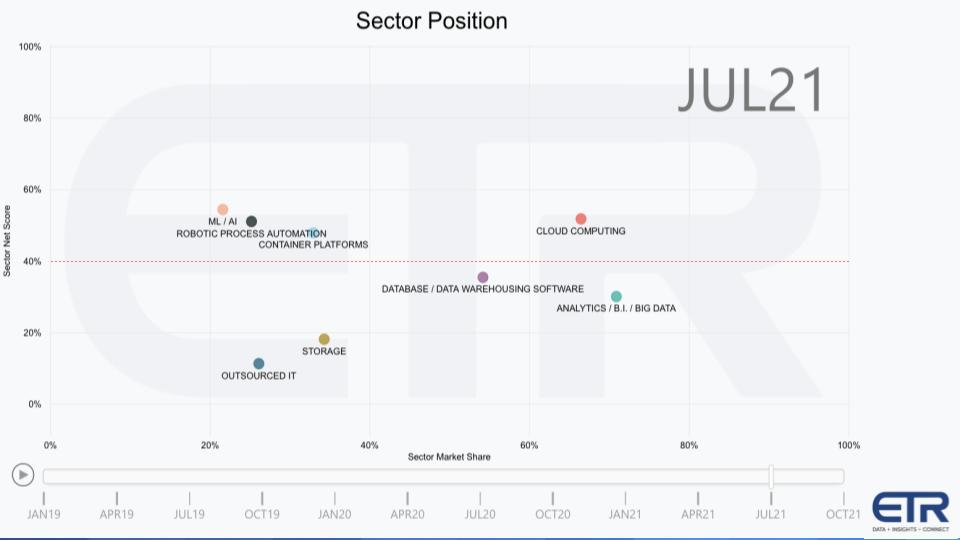
The graphic depicts the spending profiles in the ETR data set for some of the data-related sectors in the ETR taxonomy. The Y axis shows Net Score or spending momentum and the horizontal axis is Market Share or presence in the data set.
The red line at 40% represents an elevated level of spending velocity. For the past eight quarters or so we’ve seen ML/AI, RPA, containers and cloud as the four areas where CIOs and technology buyers have shown the highest Net Scores. As we’ve said what’s so impressive for cloud is it’s both pervasive and demonstrates high velocity. And we’ve plotted three other data-related areas, database/EDW, Analytics/BI/Big Data. And storage. The first two, while under the red line are still elevated. The storage market continues to plod along. And we plotted outsourced IT just to balance the chart for context.
We would point out that these areas, AI, automation, containers and cloud…are all relevant to data and represent fundamental building blocks for data architectures. Database and analytics are directly related as is storage. So that gives you a picture of the spending by sector.
No Lack of Data Tooling

The chart above is a taxonomy put together by Matt Turck who is a VC and he called this the MAD landscape – Machine learning AI and Data. The key point here is there is no lack of tooling in the big data landscape. We don’t need more tools to succeed at data mesh.
I think we have plenty of tools. What’s missing is a meta-architecture that defines the landscape in a way that it’s in step with organizational growth and then defines that meta-architecture in a way that these tools can actually inter-operate and integrate really well. The clients right now have a lot of challenges in terms of picking the right tool, regardless of the technology path they pursue. Either they have to go in bite big into a big data solution and then try to fit the other integrated solutions around it. Or, as you see, go to that menu of large lists of applications and spend a lot of time trying to integrate and stitch these two things together. So, I’m hoping that data mesh creates that kind of meta-architecture for tools to inter-operate and plug in and I think our conversation today around self-serve data platform hopefully illuminate that.
The Four Core Principles of a Data Mesh Architecture
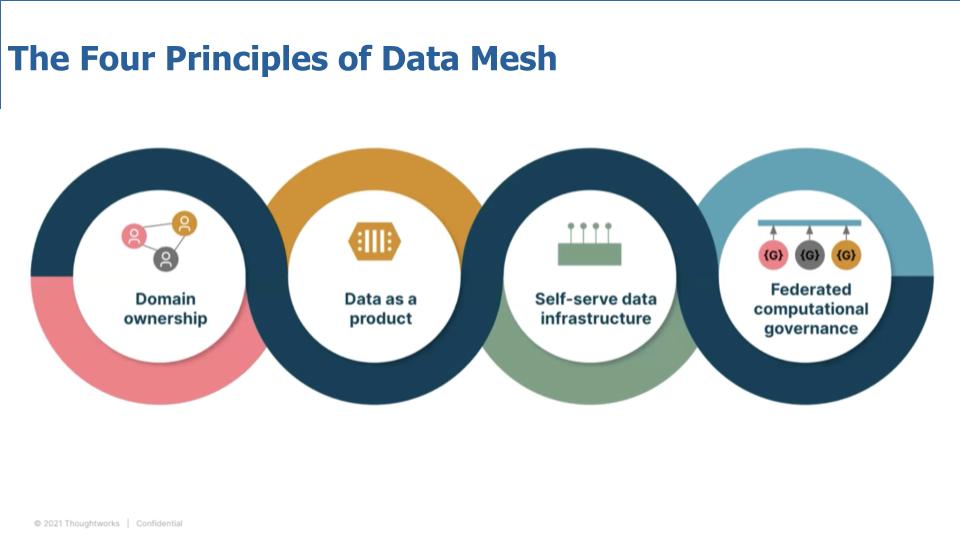
The chart above depicts the four important principles that underpin the data mesh concept.
A big frustration we hear from practitioners is that the data teams don’t have domain context. The data team is separated from the lines of business and as a result they have to constantly context switch and as such there’s a lack of alignment with business goals. So principle #1 is focused on putting end-to-end data ownership in the hands of the domain or business lines.
The second principle is data as product, which does cause people’s brains to hurt sometimes but that’s a key component. The idea that data is used to create products that can be monetized…or services that can cut costs or save lives…however an organization measures value, data is an ingredient that can be packaged for consumption.
This leads to principle #3 – self-serve data infrastructure, which we’ll drill into a bit today. A self-serve data platform reduces organizational choke points. The nuance here, is rather than just enabling self-service for technical specialists, the platform should serve a broader range of generalists with business or domain context.
And finally, principle #4 relates to a question we always get when introducing data mesh to audiences – i.e. how to enforce governance in a federated model.
The Four Principles are Interdependent 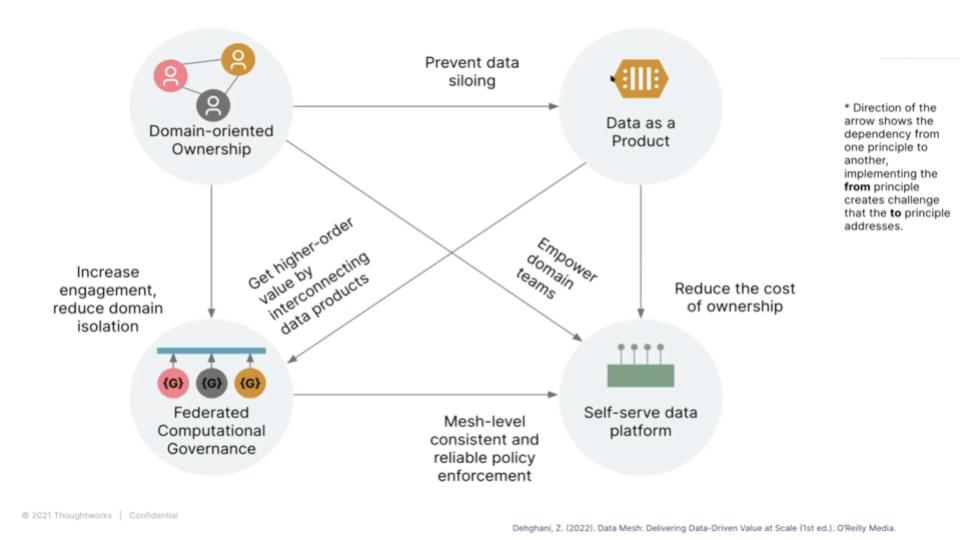
Zhamak Dehghani explains these interrelationships in this clip. And describes the relationships across the four principles as follows:
Principle #1 – Pushing Accountability to the Domains
The root cause we’re trying to address is the siloing of the data external to where the action happens, where the data gets produced, where the data needs to be shared, where the data gets used. In the context of the business. The root cause of the centralization problem gets addressed by distribution of the accountability into it, back to the domains and these domains, this distribution of accountability, technical accountability, to the domains has already happened. In the last decade or so, we saw the transition from one general IT group addressing all of the needs of the organization to technology groups within the IT department, or even outside of IT, aligning themselves to build applications and services that the different business units need.
So, what data mesh does, it just extends that model and say, “Okay, we’re aligning business with the tech and data now, right?” So, both application of the data in ML or insight generation in the domains related to the domains needs, as well as sharing the data that the domains are generating with the rest of the organization.
Principle #2 – Data as a Product as Silobuster
But, the moment you do that, then you have to solve other problems that may arise and that gives birth to the second principle, which is about data as a product, as a way of preventing data siloing happening within the domain. So, changing the focus of the domains that are now producing data from, I’m just going to create that data collect for myself and that satisfied my needs, to, in fact, the responsibility of domain is to share the data as a product with all of the wonderful characteristics that a product has and I think that leads to really interesting architectural and technical implications of what actually constitutes data as a product.
Principle #3 – Self-serve Data Platform Enables Generalists
But, once you do that, then that’s the point in the conversation that CIO says, “Well, how do I even manage the cost of operation if I decentralize building and sharing data to my technical teams, to my application teams? Do I need to go and hire another hundred data engineers?” And I think that’s the role of a self-serve data platform in the way that it enables and empowers generalist technologies that we already have in the technical domains, that the majority population of developers use these days. So, the data platform attempts to mobilize the generalist technologies to become data producers, to become data consumers, and really rethink what tools these people need. So the platform is meant to give autonomy to domain teams, empower them and reduce the cost of ownership of building and managing data products.
Principle #4 – Automate De-centralized Governance
The last principle addresses the question around, “How do I still assure that these different data products are interoperable, are secure, respecting privacy, now in a decentralized fashion?” When we are respecting the sovereignty or the domain ownership of each domain, and that leads to this idea of – from the perspective of an operational model – applying some sort of a federation where the domain owners are accountable for interoperability of their data product. They have incentives that are aligned with global harmony of the data mesh as well as from the technology perspective, thinking about this data as a product with a new lens, with a lens that all of those policies that need to be respected by these data products, such as privacy, such as confidentiality, can we encode these policies as computational, executable units and then code them in everyday products so that we get automation, we get governance through automation?
That’s the relationship, the complex relationship, between the four principles.
Goals of Data Mesh
The objective of data mesh according to Dehghani is to exchange a new unit of value between data producers and data consumers and that unit of value is a data product. A goal is to lower the ‘cognitive load’ on our brains and simplify the way in which data are presented to both producers and consumers. And doing so in a self-serve manner eliminates the tapping on the shoulder or emails or raising tickets to find out where the data lives…how should it be properly used…who has access to it, etc.
Dehghani stressed the following points:
Initially, when this whole idea of a data-driven innovation came to exist and we needed all sorts of technology stacks, we centralized creation of the data and usage of the data, and that’s okay when you first get started where the expertise and knowledge is not yet diffused and it’s only the privilege of a very few people in the organization. But, as we moved to a data-driven innovation cycle in the organization, and as we learn how data can unlock new programs, new models of experience, new products, then it’s really, really important to get the consumers and producers talk to each other directly without a broker in the middle.
Because, even though that having that centralized broker could be a cost-effective model, but if we include the cost of missed opportunity for something that we could have innovated but we missed that opportunity because of months of looking for the right data, then the cost benefit parameters and formula changes. So, to have that data-driven innovation, embedded into every domain, every team, we need to enable a model where the producer can directly, peer-to-peer, discover the data, understand it, and use it. So, the litmus test for that would be going from a hypothesis that, as a data scientist, I think there is a pattern, and there is an insight in the customer behavior that, if I have access to all of the different information about the customer, all of the different touch points, I might be able to discover that pattern and personalize experience of my customer. The litmus test is going from that hypothesis to finding all of the different sources, be able to understand, and then be able to connect them and then turn them into training of machine learning and the rest is, I guess, known as an intelligent product.
Comparing Traditional Monolithic Data Models to Data Mesh

The left hand side of the chart above is a curated description of Dehghani’s observations of most monolithic data platforms. They are optimized for control, they serve a centralized team that has formed around hyper-specialized roles. Further, operational stacks running enterprise software on Kubernetes and microservices are isolated from the Spark clusters managing the analytical data. And so on.
Whereas the data mesh characteristics are shown on the right hand side of the graphic, It proposes greater autonomy and the management of code, data pipelines and policy as independent entities versus a single unit. The point was made earlier that we must enable generalists and borrow from so many other examples in the industry. So it’s an architecture based on decentralized thinking that can be applied to any domain.
Zhamak Dehghani explains in this clip as follows:
If I pick a one key point from that comparison, it’s a focus on the data platform. So, the platform capabilities need to present a continuous experience from an application developer building an application that generates some data. Let’s say I have an e-commerce application that generates some data to the data product that now presents and shares that data as temporal, immutable facts that can be used for analytics to the data scientists that uses that data to personalize the experience to the deployment of that ML model now back to that e-commerce application. So, if you really look at this continuous journey, the walls between these separate platforms that we have built need to come down.
The platforms underneath that support the operational systems versus support the data platforms versus supporting the ML models, they need to kind of play really nicely together because, as a user, I’ll probably fall off the cliff every time I go through these stages of this value stream. So then, the interoperability of our data solutions and operational solutions needs to increase drastically because, so far, we’ve got away with running operational systems and application on one end of the organization, running data analytics in another, and build a spaghetti pipeline to connect them together. Neither of the ends are happy. I hear from data scientists, data analysts, pointing fingers at the application developer saying, “You’re not developing your database the right way.” And application pointing fingers say, “My database is for running my application. It wasn’t designed for sharing analytical data.” So, what a data mesh tries to do is bring these two worlds together closer because, and then the platform itself has to come closer and turn into a continuous set of services and capabilities, as opposed to these disjointed, big, isolated stacks.
APIs, Interfaces, Planes & the Data Mesh Platform Experience
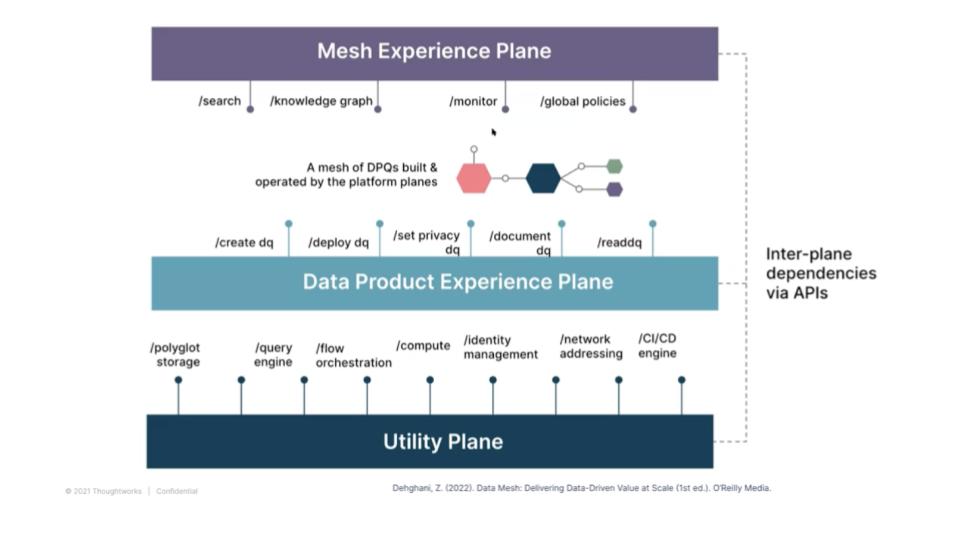
The diagram above digs deeper into the platform. It describes the various planes within the platform and the entries to and the exits from the platform. The planes represent functionality such as the underlying infrastructure in the utility plane. A plane that enables data products to be discovered and shared and a plane that enforces policies.
Dehghani explains the diagram in this clip and below:
A Technology Agnostic Platform With Cohesive Connection Points
When we think about capabilities that enables build of our application, builds upon our data products, build better analytical solutions, usually we jump too quickly to the deep end of the actual implementation of these technologies, right? “Do I need to go buy a data catalog? Or, do I need some sort of a warehouse to store it?” And, what I’m trying to kind of elevate us up and out is to force us to think about interfaces on APIs, the experiences that the platform needs to provide to run these secure, safe, trustworthy, performant mesh of data products and, if you focus on, the interfaces, the implementation underneath can swap out.
So, you can swap one for the other over time. So, that’s the purpose of having those lollipops and focusing and emphasizing, what is the interface that provides a certain capability like the storage, like the data product life cycle management and so on.
The purpose of the planes, the mesh experience plane, data product experience and utility plane, is really giving us a language to classify different sets of interfaces and capabilities that play nicely together to provide that cohesive journey of a data product developer data consumer.
The Utility Plane
The three planes are really around, okay, at the bottom layer, we have a lot of utilities. We have that Matt Turek’s kind of MAD data tooling chart. So, we have a lot of utilities right now. They manage workflow management. They do data processing. You’ve got your spark link. You’ve got your storage. You’ve got your lake storage. You’ve got your time series of storage. We’ve got a lot of tooling at that level.
Building a Data Products Plane
The layer that we kind of need to imagine and build today we don’t buy yet, as far as I know, is this layer that allows us to exchange that unit of value. To build and manage these data products. So, the language and the APIs and interface of this product experience plane is not, oh, I need this storage or I need that workflow processing. It’s that I have a data product. It needs to deliver certain types of data. So, I need to be able to model my data.
As part of this data product, I need to write some processing code that keeps this data constantly alive because it’s receiving upstream, let’s say, user interactions with a website and generating the profile of my users. So, I need to be able to write that. I need to serve the data. I need to keep the data alive and I need to provide a set of SLOs and guarantees for my data, so that good documentation, so that someone who comes to the data product knows, what’s the cadence of refresh, what’s the retention of the data, and a lot of other SLOs that I need to provide.
A Governance and Policy Plane
Finally, I need to be able to enforce and guarantee certain policies in terms of access control, privacy encryption, and so on. So, as a data product developer, I just work with this unit, a completely autonomous, self-contained unit, and the platform should give me ways of provisioning this unit and testing this unit and so on.
That’s kind of why I emphasize on the experience, and, of course, we’re not dealing with one or two data product. We’re dealing with a mesh of data products. So, at the kind of mesh level experience, we need a set of capabilities and interfaces to be able to search the mesh for the right data, to be able to explore the knowledge graph that emerges from this interconnection of data products, and we need to be able to observe the mesh for any anomalies.
Did we create one of these giant master data products that all the data goes into and all the data comes out of? Have we found ourselves a bottleneck? So, be able to do those mesh level capabilities, we need to have a certain level of APIs and interfaces.
And, once we decide what constitutes that to satisfy this mesh experience, then we can step back and say, “Okay, now what sort of a tool do I need to build or buy to satisfy them?” And that’s not what the data community or data part of our organizations are used to. I think, traditionally, we’re very comfortable with buying a tool and then changing the way we work to serve the tool and this is slightly inverse to that model that we might be comfortable with.
Practical Advice for Those Implementing Data Mesh
Data mesh is not a 60 or 90 day project. It’s an organizational mindset, architectural evolution (or revolution of sorts) and a completely different way of thinking about data value at scale. But the changes proposed by data mesh need to be approached thoughtfully and implemented over a period of time in a maturity model.

In this clip, Dheghani describes the diagram and some additional practical advice:
The graphic above was a few starting points for people who are embarking on building or buying the platform that enables the mesh creation. So, it was a bit of a focus on the platform angle and I think the first one is what we just discussed. Instead of thinking about mechanisms that you’re building, think about the experiences that you are enabling. Identify who are the people. What is the persona of data scientists? I mean, data scientists has a wide range of personas, or data product developer is the same. What is the persona I need to develop today or enable and empower today? What skillsets do they have? And so, thinking about experience mechanisms, I think we are at this really magical point. I mean, how many times in our lifetime, we come across a complete blank, kind of white space to a degree to innovate.
So, let’s take that opportunity and use a bit of creativity while being pragmatic. Of course, we need solutions today or yesterday. But, to still think about the experience as not mechanisms that we need to buy. So, that was kind of the first step and the nice thing about that is that there is an iterative path to maturity of your data mesh. I mean, if you started with thinking about, okay, which are the initial use cases I need to enable? What are the data products that those use cases depend on that we need to unlock? And what is the persona of, or general skillset of my data product developer? What are the interfaces I need to enable? You can start with the simplest possible platform for your first two use cases and then think about, okay, the next set of data developers, they have a different set of needs.
Maybe today, I just enable the SQL-like querying of the data. Tomorrow, I enable the data scientist file-based access of the data the day after I enable the streaming aspect. So, you have this evolutionary kind of path ahead of you, and don’t think that you have to start with building out everything. I mean, one of the things we’ve done is taking this harvesting approach that you work collaboratively with those technical, cross functional domains that are building the data products and see how they are using those utilities and harvesting what they are building as the solutions for themselves back into platform.
But, at the end of the day, we have to think about mobilization of the largest population of technologies we have. We have to think about diffusing the technology and making it available and accessible by the generalist technologists; and recognize that we’ve come a long way.
We’ve gone through these sort of paradigm shifts before in terms of mobile development, in terms of functional programming, in terms of cloud operation. It’s not that we are struggling with learning something new, but we have to learn something that works nicely with the rest of the tooling that we have in our toolbox right now. So, again, put that generalist as one of your center personas, not the only person of course, we’ll have specialists. Of course, we’ll always have data scientists specialists, but any problem that can be solved as a general kind of engineering problem, and I think there’s a lot of aspects of data mesh that can be just a simple engineering problem. Let’s approach it that way and then create the tooling to empower those generalists.
Words Matter

We’ll close with some thoughts from the community and questions we often receive.
Data is More than the New Oil
Oil is a finite resource. Data is not. The exact same data can be used for many different use cases and applications but a single quart of oil can only be used in one application.
Here’s how Dehghani describes her reaction to this often used phrase.
I don’t respond to those data is the gold or oil or whatever scarce resource, because, as you said, it evokes a very different emotion. It doesn’t evoke the emotion of, I want to use this. It feels like I need to kind of hide it and collect it and keep it to myself and not share it with anyone. It doesn’t evoke that emotion of sharing. I really do think that data and, with a little asterisk, and I think the definition of data changes, and that’s why I keep using the language of data products or data quantum. Data becomes the most important, essential element of existence of computation. What do I mean by that? I mean that a lot of applications that we have written so far are based on logic, imperative logic.
If this happens, do that and else do the other, and we’re moving to a world where those applications generating data that we then look at and the data that’s generated becomes the source, the patterns that we can explore it, to build our applications, as in, curate the weekly playlist for Dave, every Monday, based on what he has listened to and other people have listened to based on his profile. So, we’re moving to the world that is not so much about applications using the data necessarily to run their businesses. That data is really, truly is the foundational building block for the applications of the future. And then I think in that we need to rethink the definition of the data, and maybe that’s for a different conversation, but, I really think we have to converge the processing and the data together, the substance and the processing together, to have a unit that is a composable, reusable, trustworthy.
And that’s the idea behind the kind of data product as an atomic unit of what we build from future solutions.
Is Data an Asset That Should Someday be a Line Item on the Balance Sheet?
“Data is our most valuable asset” is another popular phrase. But the idea of sharing assets is somewhat antithetical to the notion of data sharing.
I think it’s actually interesting you mentioned that because I read the new policy in China that CFOs actually have a line item around the data that they capture. We don’t have to go to the political conversation around authoritarian of collecting data and the power that creates and the society that leads to, but that aside, that big conversation, little conversation, aside, I think you’re right. I mean, the data as an asset generates a different behavior. It creates different performance metrics that we would measure. I mean, before conversation around data mesh came to kind of exist, we were measuring the success of our data teams by the terabytes of data they were collecting, by the thousands of tables that they had stamped as golden data.
None of that leads to necessarily, there’s no direct line I can see between that and actually the value that data generated. But, if we invert that, so that’s why I think it’s a rather harmful because it leads to the wrong measures and metrics to measure for success. So, if you’re invert that to a bit of product thinking or something that you share to delight the experience of users, your measures are very different. Your measures are the happiness of the user, the decreased lead time for them to actually use and get value out of it, the growth of the population of the users. So, it works in a very different kind of behavior and success metrics.
Can I Finally Retire my Data Warehouse?
Data lake, data hub, data warehouse, S3 buckets…these are nodes on the data mesh. They don’t have to be eliminated, but rather data mesh should be inclusive of any of these technologies.
Zhamak Dehghani provides her perspective in this clip.
I think that real shift is from a centralized data warehouse to data warehouse where it fits. So, I think if we just crossed that centralized piece, we’re all in agreement that data warehousing provides interesting capabilities that are still required, perhaps as a edge node of the mesh, that is optimizing for certain queries, let’s say financial reporting, and we still want to direct a fair bit of data into a node that is just for those financial reportings and it requires the precision and the speed of operation that the warehouse technology provides. So, I think definitely that technology has a place.
Where it falls apart is when you want to have a warehouse to rule all of your data and canonically model your data because you have to put so much energy into harnessing this model and create this very complex and fragile snowflake schemas and so on that it’s all you do. You spend energy against the entropy of your organization to try to get your arms around this model and the model is constantly out of step with what’s happening in reality, because the reality of the business is moving faster than our ability to model everything into one canonical representation. I think that’s the one we need to challenge, not necessarily application of data warehouse on a node.
Lack of Standards is the Glaring Gap Today
Dehghani has specifically envisioned data mesh to be technology agnostic. And of course we nonetheless, still like to evaluate a specific vendor’s technology platform through a data mesh filter. The reality is – per the Matt Turck chart we showed earlier – there are lots of technologies that can be nodes within the data mesh…or facilitate data sharing or governance, etc. But there’s clearly a lack of standardization.
We’re not sanguine that the vendor community will drive this – but perhaps like Kubernetes, Google or some other Internet giant will contribute something to open source that addresses the problem and it will become a de facto standard.
We asked Zhamak to describe in a bit of detail, her thoughts on what kinds of standards are needed and where will they come from?
She shares her thoughts in this clip summarized below:
The vendors are not today incentivized to create those open standards because majority of the vendors, not all of them, but some vendor’s operational model is about bringing your data to my platform and then bring your computation to me and all will be great and that will be great for a portion of the clients, a portion of environments where that complexity we’re talking about doesn’t exist. So, we need, yes, other players, perhaps, maybe some of the cloud providers or people that are more incentivized to open their platform, in a way, for data sharing. So, as a starting point, I think standardization around data sharing. So, if you look at the spectrum right now, we have a de facto standards.
It’s not even a standard for something like SQL. I mean, everybody’s bastardized SQL and extended it with so many things that I don’t even know what the standard SQL is anymore, but we have that for some form of a querying. But, beyond that, I know for example, folks at Databricks to start to create some standards around their data sharing and sharing the data in different models. So, I think data sharing as a concept, the same way that APIs were about capability sharing. So, we need to have the data APIs, or analytical data APIs, and data sharing extended to go beyond simply SQL or languages like that.
I think we need standards around computational policies. So, this is, again, something that is formulating in the operational world. We have a few standards around, how do you articulate access control? How do you identify the agents who are trying to access with different authentication? The kinds of, we need to bring some of those or add our own data-specific articulation of policies.
Something as simple as identity management across different technologies is non-existent. So, if you want to secure your data across three different technologies, there is no common way of saying who’s the agent that is acting to access the data. Can I ask that to kids and authorize them? So, so those are some of the very basic building blocks.
And then, the gravy on top would be new standards around enriched kind of semantic modeling of the data. So, we have a common language to describe the semantic of the data in different nodes, and then relationship between them.
We have prior work with RDF and folks that we’re focused on, I guess, linking data across the web with the kind of the data web, I guess, work that we had in the past. We need to revisit those and see their practicality in an enterprise context. So, data modeling, rich language for data semantic modeling and data connectivity. Most importantly, I think those are some of the items on my wish list.
We’ll leave it there for now. Many thanks to Zhamak Dehghani for her continued excellent work and contributions to our program. For a deeper dive on this topic you can check out this session Zhamak did with her colleagues and hear the added perspectives of a data scientist.
Keep in Touch
Remember we publish each week on this site and siliconangle.com. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon/SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.


