Much of the energy around data innovation that dispersed with the decline of Hadoop’s relevance is coalescing in a new ecosystem spawned by the ascendency of Snowflake’s Data Cloud. What was once seen as a simpler cloud data warehouse and good marketing with Data Cloud, is evolving rapidly with new workloads, a vertical industry focus, data applications, monetization and more. The question is will the promises of data be fulfilled this time around or is it same wine, new bottle?

In this Breaking Analysis we’ll share our impressions of Snowflake Summit 2022 including the announcements of interest, major themes, what was hype, what was real, the competitive outlook and some concerns that remain in customer pockets and within the ecosystem.
Snowflake Summit 2022
The event was held at Caesar’s Forum. Getting to and from the conference venue took you through a sea of Vegas tourists that didn’t seem to be concerned one bit about the stock market, inflation or recession. The event itself was packed. Nearly ten thousand people attended. Here’s how Snowflake’s CMO Denise Persson described how this event has evolved:
Three years ago we were about 1,800 people at the Hilton in San Francisco. We had about 40 partners attending. This week we’re close to 10,000 attendees here. Almost 10,000 people online as well. And over 200 partners here on the show floor.
[Listen to Snowflake CMO Denise Persson on theCUBE describe the growth of Snowflake Summit].
Those numbers from 2019 are reminiscent of the early days of Hadoop World, which was put on by Cloudera. Cloudera mistakenly handed off the event to O’Reilly Media as the article inserted below discusses. The headline almost got it right. Hadoop World ultimately was a failure but it didn’t have to be. O’Reilly deleted Hadoop World from the name, elbowed Cloudera out of the spotlight and then killed Strata when it became less lucrative.
Snowflake Summit has filled the void.

Ironically, the momentum and excitement from Hadoop’s early days could have stayed with Cloudera but the beginning of the end was when they gave the conference over to O’Reilly. We can’t imagine Frank Slootman handing the keys to the kingdom to a third party.
Serious business was done at this event. Substantive deals. Sales people from a host sponsor and the ecosystems that support these events love physical meetups. Belly to belly interactions enable relationship building, pipeline and deals. And that was blatantly obvious at this show. Similarly noted by the way in other CUBE events we’ve done this year. But this one was a bit more vibrant because of its large attendance, growth, focus on monetization and the action in the ecosystem.
Vibrant Ecosystem: A Fundamental Characteristic of Every Cloud Company

We asked Frank Slootman on theCUBE – was this ecosystem evolution by design or did Snowflake just stumble into it? Here’s what he said:
Well, you know when you are a data cloud and you have data, people want to do things you know with that data, they don’t want to just run data operations, populate dashboards and run reports. Pretty soon, they want to build applications. And after they build applications, they want to build businesses on it. So it goes on and on. It drives your development to enable more and more functionality on that data cloud. Didn’t start out that way. We were very much focused on data operations. Then it becomes application development and then it becomes, “hey, we’re developing whole businesses on this platform.” So it’s similar to what happened to Facebook in many ways.
[Listen to Frank Slootman discuss the evolution of Snowflake’s value to the ecosystem].
Perhaps a little bit of both design and seizing an organic opportunity.
The Facebook analogy is interesting because Facebook is a walled garden. So is Snowflake. But when you come into that garden you have assurances that things are going to work in a very specific way because a set of standards and protocols is being enforced by a steward. This means things run better inside of Snowflake than if you try to do all the integration yourself. All that said, Snowflake announced several moves to make its platform more accommodating to open source tooling and bring optionality to customers.
Unpacking the Key Announcements at Snowflake Summit
We’re not going to do a comprehensive overview on all the announcements but we will make some overall comments and share what some of the analysts in the community said on theCUBE. As well, Matt Sulkis from Monte Carlo wrote a nice overview the keynotes and a number of analysts like Sanjeev Mohan, Tony Baer and others are posting their analysis on the announcements.
We will make the following comments.
Unistore. Unistore extends the type of data that can live in the Snowflake Data Cloud by enabling transactional data. Unistore is enabled by a feature called Hybrid Tables, which is a new table type in Snowflake. One of the big knocks against Snowflake is couldn’t handle transaction data. Several database companies are creating this notion of a hybrid where both analytic and transactional workloads can live in the same data store. Oracle is doing this for example with MySQL Heatwave, enabling many orders of magnitude of reduction in query times with much lower costs. We saw Mongo earlier this month add an analytics capability to its primarily transactional platform. And there are many others approaching the converged database path.
Community Hot Takes
Here’s what Constellation Research analyst Doug Henschen said about Snowflake’s moves into transaction data:
With Unistore, [Snowflake] is reaching out and trying to bring transactional data in. Hey, don’t limit this to analytical information. And there’s other ways to do that, like CDC and streaming, but they’re very closely tying that again to their marketplace, with the idea of bring your data over here and you can monetize it. Don’t just leave it in that transactional database. So another reach to a broader play across a big community that they’re building.
[Listen to Constellation Research Analyst Doug Henschen’s point of view on Unistore].
Snowpark and Streamlit. Snowflake is expanding workload types in a unique way and through Snowpark and its Streamlit acquisition, enabling Python so that native apps can be built in the Data Cloud and benefit from all the structure, features, privacy, governance, data sharing and other features that Snowflake has built and the ecosystem enables. Hence the Facebook analogy that Frank Slootman put forth…or the Apples’ App Store may also be apropos. Python support also widens the aperture for machine intelligence workloads.
We asked Snowflake’s SVP of product, Christian Kleinerman, which announcement he thought was most impactful. Despite the “who is your favorite child” nature of the question, he did answer – Here’s what he said:
I think native applications is the one that looks like, eh, I don’t know about it on the surface, but it has the biggest potential to change everything. That’s create an entire ecosystem of solutions within a company or across companies. I don’t know that we know what’s possible.
Apache Iceberg. Snowflake also announced support for Apache Iceberg, which is a new open table format standard that’s emerging. So you’re seeing Snowflake respond to concerns about its lack of openness.
Here’s what former Gartner analysts Sanjeev Mohan said about the motivation for Snowflake to embrace Apache Iceberg; and what it means for customers.
Primarily, I think it is to counteract this whole notion that once you move data into Snowflake, it’s a proprietary format. So I think that’s how it started, but it’s hugely beneficial to the customers, to the users, because now if you have large amounts of data in parquet files, you can leave it on S3, but then you, using the Apache Iceberg table format in Snowflake, get all the benefits of Snowflake’s optimizer. So for example, you get the micro partitioning, you get the metadata. So, in a single query, you can join, you can select from a Snowflake table Union and select from an Iceberg table and, and you can do stored procedures and user defined functions.
So I, think they, what they’ve done is extremely interesting. Iceberg by itself still does not have multi-table transactional capabilities. So if I am running a workload, I might be touching 10 different tables. So if I use Apache Iceberg in a raw format, they don’t have it, but Snowflake does.
Cost Optimization. Costs are becoming a major concern with consumption models like AWS and of course Snowflake. The company showed some cost optimization tools – both from themselves and the ecosystem, notably Capital One, which launched a software business on top of Snowflake, focused on optimizing costs.
Governance, Cross-cloud, On-prem & Security. Snowflake and its ecosystem announced many features around governance, cross-cloud (supercloud), a new security workload and they re-emphasized their ability to read non-native on-prem data into Snowflake through partnerships with Dell and Pure. And more.
Here’s a clip from theCUBE and some deeper analysis from David Menninger of Ventana Research, Sanjeev Mohan of SanjMo andTony Baer of dbInsight. To get the full picture…
Here are some excerpts from the conversation:
Dave Menninger, Ventana Research
[Ventana] research shows that the majority of organizations, the majority of people, do not have access to analytics. And so a couple of the things they’ve announced address those or help to address those issues very directly. Snowpark and support for Python and other languages is a way for organizations to embed analytics into different business processes. And so I think that’ll be really beneficial to try and get analytics into more people’s hands. And I also think that native applications, as part of the marketplace, is another way to get applications into people’s hands, rather than just analytical tools. Because most people in the organization are not analysts. They’re doing some line of business function. They’re HR managers, they’re marketing people, they’re sales people, they’re finance people. They’re not sitting there mucking around in the data, they’re doing a job.
Sanjeev Mohan, SanjMo
The way I see it is Snowflake is adding more and more capabilities right into the database. So for example, they’ve gone ahead and added security and privacy. So you can now create policies and do even cell level masking, dynamic masking. But most organizations have more than Snowflake. So what we are starting to see all around here is that there’s a whole series of data catalog companies, a bunch of companies that are doing dynamic data masking, security and governance, data observability, which is not a space Snowflake has gone into. So there’s a whole ecosystem of companies that, that is mushrooming.
Tony Baer, dbInsight
Well, put this way. I think of this as the last mile. In other words, you have folks that are basically very comfortable with Tableau [for example], but you have developers who don’t want to have to shell out for a separate tool. And so this is where Snowflake is essentially working to address that constituency. To Sanjeev’s point, I think part of what makes this different from the Hadoop era is the fact that these capabilities and a lot of vendors are taking it very seriously to make this native [inside of Snowflake]. Now, obviously Snowflake acquired Streamlit. So we can expect that the Streamlit capabilities are going to be native.
A Modern Data Stack is Emerging to Support Monetization

The chart above is from Slootman’s keynote. It’s his version of the modern data stack. Starting at the bottom and moving up the stack…Snowflake was built on the public cloud. Without AWS, there would be no Snowflake. Snowflake is all about data and mobilizing data – hence live data – and expanding the types of data including structured, unstructured, geospatial and the list goes on. Executing on new workloads – started with data sharing, they recently added security and now Snowflake has essentially created a PaaS layer – a superpaas layer if you will – to attract application developers. Snowflake has a developer-focused event coming in November. And they’ve extended the marketplace with 1300 native apps listings and at the top of the list, the holy grail…monetization.
Here’s the thing about monetization. There’s a lot of talk in the press, on Wall Street and in the community about consumption-based pricing and how spending on analytics is discretionary. But if you’re a company building apps in Snowflake and monetizing – like Capital One intends to do…and you’re now selling in the marketplace…that is not discretionary. Unless your costs are greater than your revenue, in which case it will fail anyway.
But the point is we’re entering a new era where data apps and data products are beginning to be built – and Snowflake is attempting to make the data cloud the de facto place to build them.
Big Themes at Snowflake Summit 2022

Bringing apps to the data instead of moving the data to the apps. Reminiscent of Hadoop’s promise to bring compute to data. The problem is much of the important, high velocity data moved into the cloud and left the Hadoop vendors behind. But this phrase was a constant refrain at the event and one that certainly makes sense from a physics point of view.
But having a single source of data that is discoverable, sharable and governed, with increasingly robust ecosystem options is unique and a differentiator for Snowflake. We’ve yet to see a data ecosystem that is as rich and growing as fast. And the ecosystem is making money (monetization), which we discussed above.
Industry clouds – Financial services, healthcare, retail and media – all front and center at the event. Our understanding is Slootman was a major force behind this new focus and go to market effort. We believe this is an example to align with customers’ missions and objectives. In particular, gaining a deeper understanding within industries of what it takes to monetize with data as a differentiating ingredient.
We heard a ton about data mesh. There were numerous presentations about the topic and we’ll say this. If you map the seven pillars Snowflake talks about into Zhamak Dheghani’s Data Mesh framework, they align better than most of the “data mesh-washing” that we’ve seen.
Snowflake’s seven pillars are: All data, all workloads, global architecture, self-managed, programmable, marketplace and governance.
While we see data mesh as an architectural and organizational framework, not a product or a single platform, when you map some of these seven pillars into the four principles of data mesh (domain ownership, data as product, self-service infrastructure and computational governance) they align fairly well.
To wit…All data -perhaps with hybrid tables that becomes more of a reality. Global architecture, means the data is globally distributed to support decentralized data and domain ownership. Self-managed aligns with self-serve infrastructure and inherent governance with the fourth principle. And with all the talk about monetization that aligns with data as product.
To its credit, Snowflake doesn’t use data mesh in its messaging (anymore). Even though many of its customers do so. And while the data cloud is not completely aligned with data mesh concepts, the company is essentially building a proprietary system that substantially addresses some of the goals of data mesh; and is increasingly inclusive of open source tooling.
Supercloud – that’s our term – we saw lots of examples of clouds on top of clouds that are architected to span multiple clouds. This includes not only the Snowflake Data Cloud but a number of ecosystem partners headed in a similar direction.
Snowflake still talks about data sharing but it now uses the term collaboration in its high level messaging. Data sharing is kind of a geeky term and also this is an attempt by Snowflake to differentiate from everyone that says “we do data sharing too.”
And finally Snowflake doesn’t say data marketplace anymore…it’s now marketplace, accounting for its application market.
Snowflake’s Competitive Position
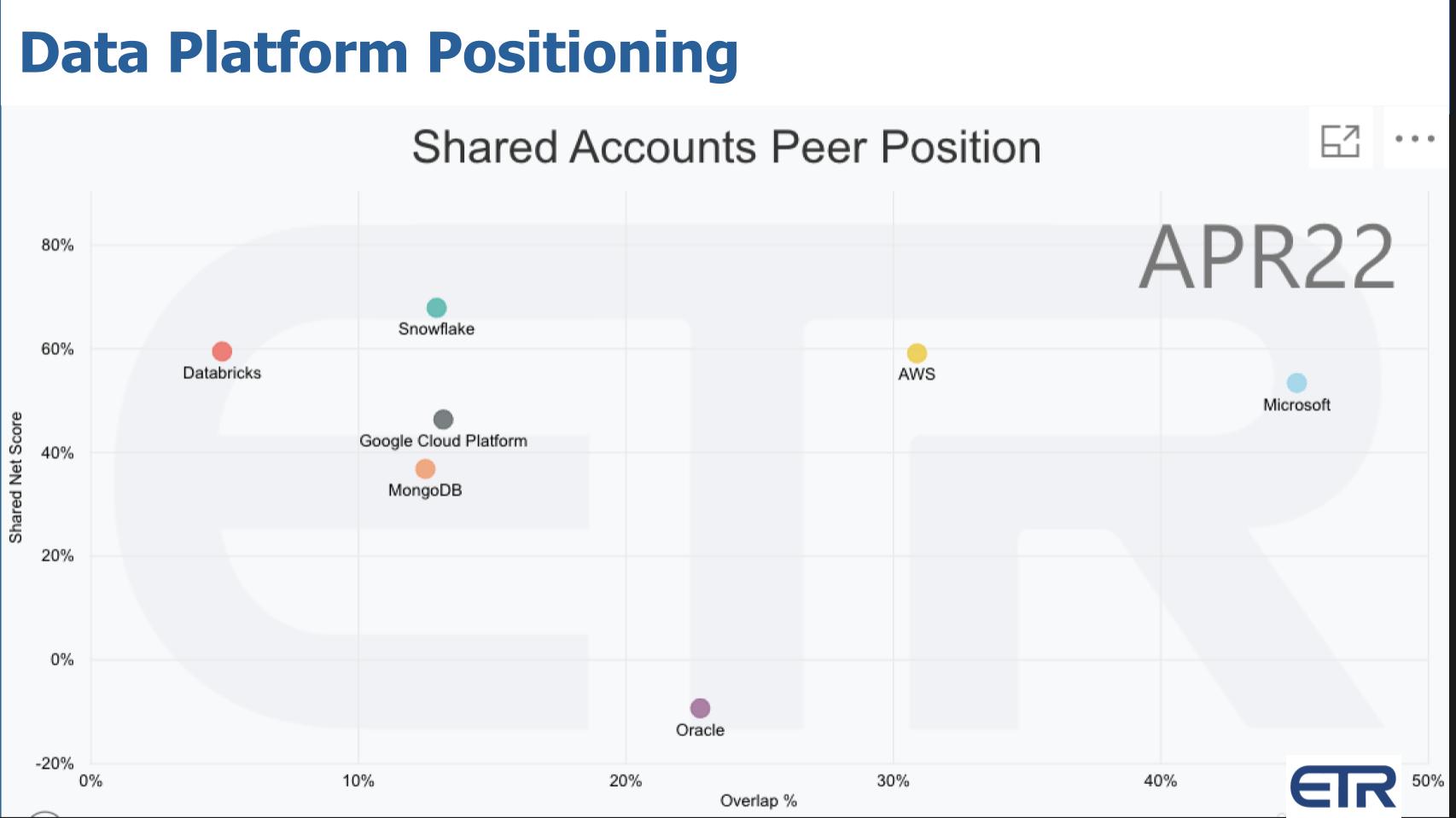
The above chart above is from ETR’s spending survey. The vertical axis is Net Score or spending momentum and the X axis is penetration in the data set called Overlap. Snowflake continues to lead all players on the Y axis but the gap is closing. Snowflake guided conservatively last quarter so we wouldn’t be surprised if that still lofty height ticks down a bit in the ETR July survey. Databricks is a key competitor obviously. It has strong spending momentum but it doesn’t have the market presence. It didn’t get to IPO during the bubble and it doesn’t have nearly as deep go to market machinery, but they’re getting attention in the market.
Some analysts, Tony Baer in particular believe Mongo and Snowflake are on a bit of a collision course long term. The cloud players are the biggest partners and the biggest competitors of Snowflake because they all have strong data products. Then there’s always Oracle, It doesn’t have nearly the spending velocity of the others but it does own a cloud and it knows a thing or two about data…and it definitely is a go to market machine.
The ETR survey doesn’t directly measure the data cloud differentiation Snowflake brings to the table. None of the other competitors have an ecosystem solely dedicated to data the way Snowflake does, not even the hyperscalers.
Customer and Ecosystem Rumblings and Grumblings
Events like this one have become a bit like rock concerts. Huge crowds, lots of loud music and tons of energy and buzz, especially when folks are making money. But when you dig for the warts you can always find them. And there continues to be healthy skepticism about Snowflake as the next big thing.
And the reason is simple. We’ve heard before how a particular technology – EDW, data hubs, MDM, data lakes, Hadoop, etc. was going to solve all of our data problems. None ever did. In fact sometimes they created more problems that allowed vendors to push more incremental technology to solve the problems they created – like tools and platforms to clean up the no schema on write mess of data lakes / data swamps.
And as practitioners know, a single technology, in and of itself, is never the answer. The organizational, people, process and associated business model friction points will overshadow the best technology every time. And disruption is always around the corner in tech.
Nonetheless, Snowflake is executing on a new vision and people are rightly excited. Below are some of the things that we heard in deep conversations with a number of customers and ecosystem partners.

Hard to keep up. First, a lot of customers and partners said they’re having a hard time keeping up with the pace of Snowflake. It’s reminiscent of AWS in 2014. The realization that every year there would be a firehose of announcements, which causes increased complexity. When it was just EC2 and S3 life was simple.
Increased complexity. We talked to several customers that said – “well yeah this is all well and good but I still need skilled people to understand all these tools that I’m integrating– catalogs, machine learning, observability, multiple governance tools and so forth. And that’s going to drive up my costs.” It’s a huge challenge for Snowflake. It has been built on its simplicity ethos. Maintaining that while continuing to innovate and integrate ecosystem partners is non-trivial.
Harder to prioritize. We heard other concerns from the ecosystem that it used to be clear as to where they could add value when Snowflake was just a better data warehouse…but to point #1 they’re either concerned they’ll be left behind or subsumed. To that we’d say the same thing we tell AWS customers and partners. If you’re a customer and you don’t keep up, you risk getting passed by the competition. If you’re a partner, you’d better move fast or you’ll get left behind when the train moves on.
Doubting Thomases. A number of skeptical practitioners, really thoughtful and experienced data pros suggested they’ve seen this moving before – i.e. same wine new bottle.
This time around we certainly hope not given all the energy and investment that is going into this ecosystem. And the fact is, Snowflake is unquestionably making it easier to put data to work. They built on AWS so you didn’t have to worry about provisioning compute, storage and networking. Snowflake is optimizing its platform to take advantage of things like Graviton– so you don’t have to.
And they’re building a data platform on which their ecosystem can create and run data applications – aka data products – without having to worry about all the ancillary difficult and non-differentiated work that needs to get done to make data discoverable, shareable and governed.
And unlike the last 10 years, you don’t have to deal with nearly as many untamed animals in the zoo. And that’s why we’re optimists about this next era of data…
Keep in Touch
Thanks to Stephanie Chan who researches topics for this Breaking Analysis. Alex Myerson is on production, the podcasts and media workflows. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE. And special thanks this week to Andrew Frick, Steven Conti, Anderson Hill, Sara Kinney and the entire Palo Alto team.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.


