 Last week at the Open Compute Summit Winter 2013 event, Facebook shared insight into its IT infrastructure. While hyperscale companies like Google, Amazon, and Facebook are quite different from the typical enterprise, it is Wikibon’s belief that those companies are driving key changes to how infrastructure is consumed that will filter down to the service provider and enterprise worlds in the near future.
Last week at the Open Compute Summit Winter 2013 event, Facebook shared insight into its IT infrastructure. While hyperscale companies like Google, Amazon, and Facebook are quite different from the typical enterprise, it is Wikibon’s belief that those companies are driving key changes to how infrastructure is consumed that will filter down to the service provider and enterprise worlds in the near future.
Standardization of Building Blocks
Jason Taylor, Facebook’s Director of Capacity Engineering Analysis (see his entire presentation here) shared the design practices for Facebook’s infrastructure. Like service providers and other large Web companies, Facebook uses homogenous building blocks rather than specialized silos that are custom built for applications wherever possible. As shown in Figure 1, Facebook has five server designs that it builds in rack architectures (each rack holding 20-40 servers). Everything is done at massive scale; in the first nine months of 2012, Facebook spent $1B for capital expenditures including servers, networking, storage and construction of data centers.
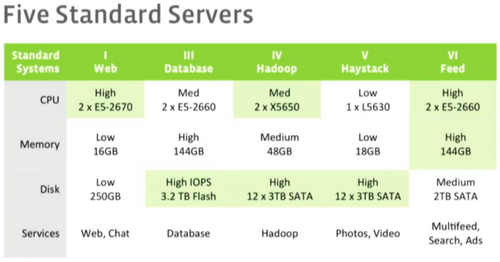
Source: Open Compute Summit Winter 2013 presentation
The “vanity free servers” (not a name brand or even a whitebox solution) are designed bare-bones to meet the compute, RAM, disk, flash and connectivity needs of the design without any other features that are normally built into a platform. Jason Taylor listed the following benefits of server standardization:
- Volume pricing,
- Repurposing (gives the ability to not just scale up, but also remove to scale down),
- Easier operations (simpler repairs, drivers and DC headcount),
- According to Delfina Eberly, Facebook’s Director of US DC Operations, it can now service over 20,000 servers per technician!
- Servers allocated in hours rather than months.
The drawbacks are that not every application fits perfectly into the available options, and as solutions and technology change over time, Facebook needs to make adjustments or risk more waste.
On the storage side, Facebook considers flash to be critical (the company is Fusion-io’s largest customer), while disk is still useful as an inexpensive price point for large capacity. See David Floyer’s write-up of how the new Fusion-io ioScale fits into the hyperscale market.
Disaggregated Rack rather than Virtualization
Facebook’s proposed solution to overcome the drawbacks of the current architecture is the creation of the Open Compute Project to develop a Disaggregated Rack, which allows independent management a replacement of the individual components of the server. The OCP project (see the press release) includes participation from Intel and the ODM supplier Quanta Computer (who is popping up in lots of places). Taylor characterized Distributed Rack as the “opposite of virtualization”. Virtualization is good for heavy idle workloads (an easy efficiency win for most enterprises), while disaggregated rack pushes servers as hard as they go and scaling/trimming is then done for efficiency. Virtualization is good for unpredictable workloads and outsourced environments. Disaggregated rack allows custom configurations (fix the issue of five servers), speeds tech refreshes and speed of innovation. Issues: physical changes and interface overhead.
Hyperscale operations
The typical enterprise spends more than 70% of budget on operations; way too much to just keep the lights on and running. At hyperscale deployments, staffing ratios must change. Budgets will not be able to support the staffing requirements for managing thousands of devices or having to deal with intricacies such as data management with traditional storage arrays.
In understanding the current staffing requirements, organizations need to look at the people involved in procuring, installing, provisioning, and maintaining storage. In addition, organizations need to understand staffing requirements for performance management, data migration, data backup, data recovery, disaster protection, security, and compliance. New architectures will enable a single individual to manage petabytes of storage, but in order to take advantage of this step-wise improvement, budgets may have to be consolidated. Just as Facebook is managing orders of magnitude more servers than an enterprise environment due to automation, toolsets and simplicity, Shutterfly manages about 70PB of object storage with 3 administrators.
Action Item: Disaggregated rack is an interesting idea, but it remains to be seen if the industry will create a solution that targets a small number of large users. Service providers and enterprise users can learn from the example of managing infrastructure at the rack level. The elimination of custom-built architecture and breaking down of silos is something that all CIOs should be looking at. The old ways of doing things are too complex and have too much overhead. Two paths of simplification are to either look at moving to a service provider that can provide IT-as-a-service or the adoption of converged infrastructure.

