This report elaborates on the role of digital business platforms for machine learning following the overview in a prior report. Specifically, it focuses on data feedback loops. The next report will focus on automated deployment.
Premise
For an emerging generation of applications, machine learning has to be part of a shared foundation. But in order to achieve pervasive adoption, that foundation needs to add additional capabilities to the digital business platforms that Wikibon has identified. In particular, data feedback loops working with machine learning are necessary to sustain differentiation.
The technology set required to build out digital business platforms for machine learning (DBPMLs) is not complete; a lot of software still must be invented. The greatest value with machine learning models ultimately comes from the data feedback loops that dynamically improve the models. But most machine learning infrastructure for setting up and managing “data feedback loops” today requires heavy involvement of data scientists at most stages in the process. While human supervision will always play a role in engineering data feedback loops for machine learning, today planning, building, and running these data feedback loops is far too labor intensive and regularly causes shops to abandon big data projects. Better automation is a necessary feature of long-term big data success. Getting there will require that:
- Data feedback loops must work like a virtuous cycle, driving ongoing business differentiation. Applications have fed telemetry data into management software for decades. Now, applications need even deeper instrumentation to feed data into machine learning models. The updated models then dynamically improve the applications. The whole feedback process is a virtuous cycle. The models use data from customers, products, and operations to continually refine customer engagement, product functionality, and operational processes.
- Data scientists have to set up the virtuous cycles. Human expertise plays a critical role in creating the virtuous cycles and putting them in motion. Data for machine learning typically comes from sources far less carefully curated than a data warehouse. The first task requires preparing and integrating the raw, uncurated data. This process is also known as data wrangling. Human subject matter expertise is even more important for extracting data that moves the needle in driving the most accurate answers from the model; this is the data that extracts the signal from the noise. This expertise is necessary to avoid polluting the model with noise, which is data that is simply correlated with the model’s answers.
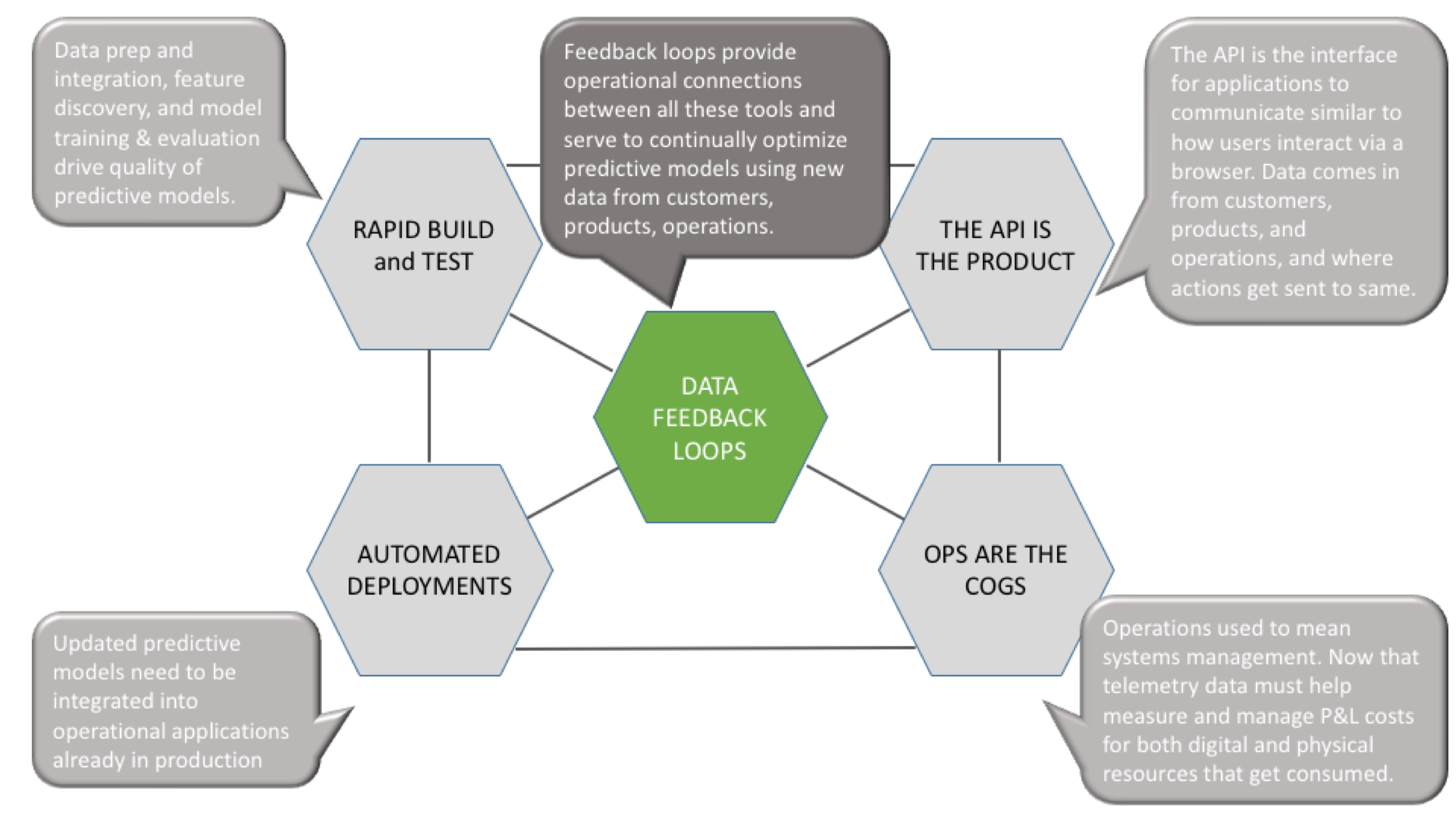
Data feedback loops drive ongoing differentiation for businesses.
Every time a user clicks on a Google search result link, they are adding to data feedback loops in Google’s search engine. A machine learning model that ranks the most relevant links uses the well-known Page Rank algorithm. But the model also dynamically refines those rankings by using data about how users click on the links over time. If more users click first on a lower-ranked link, that link gets promoted higher on the list in the future. This dynamic refinement works like a flywheel and needs to be part of improving functionality in all machine learning applications.
Under the covers, data feedback loops capture data from applications, facilitate ingestion of the data into the machine learning models, compute results as decisions or recommendations, and then send results back to consumers, which could be the same or other applications, devices like the industrial internet of things (IIoT), or end-users. Data feedback loops take effort and expertise to maintain because there is always additional, contextual data about customers, products, and operations that can improve the models. Using another example, an automotive insurer can add additional data feeds to an online insurance service that goes beyond personalized risk pricing. The insurer can incorporate other data sources to models that offer real-time safe driving coaching, navigation alerts based on weather-related hazards, and parking advice based on traffic congestion. The more drivers use this functionality, the faster the models will improve. Ultimately, network effects are central to the value of these feedback loops. Competing on the scale of the feedback loops will almost always be more important than the algorithms, barring competitive breakthroughs in the algorithms. In Google’s case, Yahoo! and Microsoft could have had just as good search algorithms, but Google’s early lead became permanent because they captured more user data about how to rank the search results early and that advantage became self-reinforcing.
Data scientists have to set up the virtuous cycles.
Before the magic of data feedback loops kick in, data scientists and subject matter experts have to prep and integrate the data (data wrangling) and then connect the right data to the right algorithms to create the initial machine learning model (feature identification). Once these two steps are complete, and the model is deployed, the feedback loops can start.
Data wrangling takes the most time but will eventually support more automation. Data wrangling is the janitorial work in data science. Raw data almost always has all sorts of elements that need to be cleaned up. A whole industry of data wrangling tools exists. They handle data-related tasks like reshaping, subsetting observations, creating new variables, combining sets, grouping, and summarizing. Machine learning may someday make data scientists and data engineers more productive, especially as it becomes easier to follow data all the way from the source feeds and applications.
Identifying the variables or features that drive the model is by far the most important task in setting up data feedback loops and the task that will likely prove hardest to automate. While machine learning tools do the huge number of calculations to help figure out the relative weighting of the features, humans have to determine which features to feed into the modeling process. In other words, humans must separate the signal from the noise. Having too many features that correlate but don’t contribute to causing a prediction creates a model with a lot of noise that’s less accurate. A large part of what makes this task so difficult is that most enterprises have a huge variety of data. Not only must data scientists separate the signal from the noise, but the data scientists typically don’t know at the beginning of a project if they have all the data necessary for building the desired model. For example, the data science team must determine if they have all the data necessary to deliver next best offers to customers. Agile development practices help determine sooner rather than later if a project can deliver on its objectives. An experimental area of deep learning, which is a type of machine learning that is very effective with speech recognition, natural language understanding, and vision, has shown some early promise at helping with feature identification. But seeing that help in products is probably several years away. So feature identification will likely continue to make the integration of data and machine learning models a key opportunity for differentiation for a long time.
Action Item
Big data pros need to identify which data feedback loops in their machine learning applications can deliver sustainable differentiation through network effects. Despite a current lack of tooling that can automate the two primary steps in setting up the data feedback loops, data wrangling and feature identification, starting early is critical because getting to scale is likely to create the “winner takes most” competitive dynamics that have become so common in tech industries. The biggest sin is to wait for the tooling to become automated enough for all competitors to jump in.


