
Premise
Building the new generation of enterprise applications requires tools and approaches for ensuring that they run seamlessly across hybrid public/private cloud environments. Developers are adopting tools and methodologies for building and deploying applications that behave the same way on-premises or in public clouds. For developers, the key is to follow “True Private Cloud” guidelines when implementing applications for deployment in hybrid public/private clouds.
Analysis
Monolithic application environments have become more of an exception than the rule in enterprise IT architectures. Increasingly, developers find themselves challenged to develop applications that span hybrid cloud environments.
Developing a hybrid application is often a bespoke exercise, with programmers writing “glue” integration code to bind their handiwork into a unified architecture. The challenge facing today’s developers is to build applications that seamlessly span hybridized blends of heterogeneous cloud offerings, operating platforms, application servers, database management systems, integration middleware, machine-learning pipelines, and other IT platforms.
That’s a tough feat to achieve, but it’s not insurmountable. Developers should build applications for hybrid cloud environments in a layered architecture. In that regard, Wikibon provides the following core guidance:
- Identify the optimal distribution of application capabilities across hybrid clouds. Developers should focus on distributing data, code, machine-learning models, and other application artifacts across hybrid clouds without impacting the service levels that users have come to expect from on-premises applications.
- Implement the most suitable mix of platforms, middleware, and tools for each capability. Developers often build hybridized solutions that span several implementation layers in a complex application architecture. In many hybrid cloud environments, there is also considerable hybridization in any or all the following layers: data, models, logic, runtimes, workloads, and programmatic abstractions.
- Compose the end-to-end application in an implementation-agnostic solution patterns. To mitigate against lock-in at any capability level in a hybrid cloud environment, developers should build solutions in high-level patterns – such as serverless computing – that are designed to be agnostic to the underlying data, programming, runtime execution, and other application capabilities. In a truly hybridization-friendly application architecture, developers should be able to blend whatever mix of platforms, middleware, and other capabilities address business requirements over the preferred hybrid-cloud configuration.
Identify Optimal Distribution Of Application Capabilities Across Hybrid Clouds
Data exerts a kind of gravitational force on application infrastructure. To the extent that data must remain within the enterprise data center—due to security, compliance, control, availability, and other business requirements—applications will tend to gravitate around it in private clouds. And as enterprises move more of their data outside their firewalls–perhaps to improve service levels and share the data more openly with customers and other stakeholders, application development will shift toward public clouds.
Hybridization is often a multi-layer phenomenon in enterprise application architectures, with data hybridization a core organizing thread in building and managing the underlying cloud infrastructure. One typical example of a hybridized application is the recommendation engine for both inbound and outbound e-commerce. In order to build out recommendation engines in hybrid cloud environments, developers and other IT professionals must :
- Write code, develop machine-learning models, compose app-to-app orchestrations, and other craft other programmatic artifacts that execute on distinct platforms;
- Leverage a complex data architecture that encompasses both transactional and analytic databases, structured and unstructured stores, predictive and streaming environments, and so on;
- Execute some capabilities (e.g, multichannel customer engagement) on a public cloud while others (e.g, order-fulfillment systems) on a private cloud;
- Run these capabilities on a thicket of computing platforms, including bare metal, virtualization, containerization, and serverless;
- Manage the end-to-end application in compliance with the policies and practices of the various organizations that offer and manage underlying third-party public and private cloud environments; and
- Maintain a tangle of application logic that was developed in a wide range of languages, tools, and programming abstractions
Ideally, distributing these capabilities across hybrid clouds need not dilute the service levels that users have come to expect from similar capabilities deployed on-premises in enterprise environments. As illustrated in Figure 1, the private-cloud-grade experience should remain intact even as data, models, code, workloads, and other application artifacts are moved back and forth in complex, hybrid multi-cloud environments. This robust hybrid-cloud experience is the essence of what Wikibon calls the “True Private Cloud.”
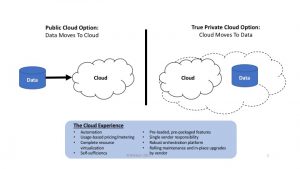
Figure 1: The True Private Cloud
For developers, building applications for a hybrid-oriented True Private Cloud delivers the following advantages:
- Self-service access, administration, and optimization across the application lifecycle;
- Agile composition, orchestration, and in-place upgrade of applications;
- On-demand provisioning of applications as collections of pre-built microservices;
- automated development, testing, and release of applications within an embedded cloud DevOps fabric;
- Single-provider responsibility, rolling maintenance, and management
- Converged logical view of all apps, data, and other resources;
- Comprehensive virtualization of application resource provisioning, access, and management;
- Usage-based pricing, metering, and chargeback for application resource usage;
- Execution of the same APIs or applications across multiple cloud environments or on-premises;
- Flexible containerization and encapsulation of functionality for flexible redeployment onto heterogeneous computing platforms;
- Dynamic shifting of application deployment targets;
- Elastic provisioning of resources across distinct environments in response to changing demands;
- Management of runtimes and workloads across distinct environments from a single management view; and
- Portability of applications between cloud and on-premises environments without rewriting code
For example, virtualizing your data environment in an edge-oriented hybrid cloud should enable you to more easily move data and deep-learning workloads transparently between devices, hubs, and cloud-based clusters to improve latencies on real-time mobile and Internet of Things applications that span those tiers. Likewise, virtualizing data security and governance across a well-architected hybrid cloud ensures a consistent level of compliance regardless of whether data and workloads have been shifted to a Hadoop cluster, a stream processing system, an enterprise data warehouse, or a data lake sitting on premise, in the public cloud, or a hybrid mixture of both.
Implement The Most Suitable Mix Of Platforms, Middleware, And Tools For Each Capability
Developers may need to build hybridized solutions that span several implementation levels in a complex application architecture. Figure 2 illustrates the principal levels of application hybridization—data, models, logic, runtimes, and workloads—within such an architecture.
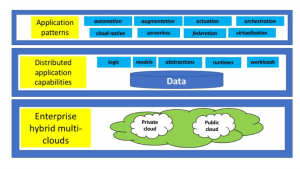 Figure 2: Hybrid Cloud Application Architecture
Figure 2: Hybrid Cloud Application Architecture
Hybrid data
Hybridizing data is one of the fundamental challenges for developers on the more complex application projects, such as building e-commerce applications that connect front-end multichannel customer engagement systems with back-end order fulfillment, manufacturing, and supply chain systems. Even when the underlying cloud is not hybridized (i.e, everything’s running in a specific private or public cloud), there may be considerable hybridization among underlying data platforms. Programmers often need to work with data that is stored, managed, and processed in two or more heterogeneous platforms, due to the fact that there is a wide range of specialized data architectures for distinct roles, workloads, and deployment models.
In a hybrid data environment, a data lake is increasingly the preferred read-only repository for data that serves diverse applications. Here are some facets of hybridization within enterprise data lakes:
- Some big data platforms may be geared to data at rest (e.g., distributed file systems, relational databases, and NoSQL platforms) while others are dedicated to processing data in motion (e.g., Kafka, Flink, Cassandra).
- Some platforms may be designed solely for handling structured data (e.g., SQL databases), while others are for unstructured and semi-structured data (e.g., Hadoop Distributed File System).
- Some data platforms may be geared to batch data processing, while others are primarily for continuous stream processing.
- Some may be optimized for fast query and transactional applications, while others handle high-volume data transformation, data cleansing, and embedded analytics workloads.
- Some, such as that implement Spark, may be dedicated to developers of machine learning, deep learning, and other artificial intelligence applications.
- Some data platforms may be engineered for guaranteed consistent transactions, while others support eventual consistency.
Hybrid models
Hybridizing models often follows from the leveraging of disparate data platforms in a complex application. What this hybridization involves is the incorporation of data-driven insights produced by diverse models for reporting, dashboarding, data mining, predictive modeling, machine learning, deep learning, graph modeling, and other analytics applications. The hybridization may involve merging of historical, current, and predictive models within applications. Developers may pull all analytics models into applications through SQL calls, REST interfaces, containerized model embedding, remote procedure calls, or any other programmatic interface. In a distributed IoT edge application, these analytics may execute alongside the data that’s persisted or streamed in any or all of the tiers, with the hybridization of device-sourced analytics managed at the hub/controller and/or cluster/cloud tiers.
Figure 3 shows one common pattern for distributing machine learning models and other data storage, processing, and analytics across hybrid cloud architectures.
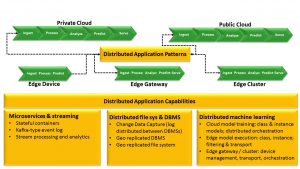
Figure 3: Distributed Data Distributed Processing Across Hybrid Clouds
Hybrid logic
Hybridizing logic is what happens when programmers drive their applications from more than procedural program code. Depending on the application’s requirements, this hybrid logic may also include analytic models, orchestration models, business models, microservice definitions, policies, metadata, semantics, schemas, state, and context information. Typically, each application platform manages its own collection of logic, with hybridization of cross-platform logic happening organically as developers bring more platforms, tools, and other environments into their project. In DevOps environments, a best practice is to manage most of the application logic from a development repository with version controls and other development governance controls built-in. Where data and analytic models are concerned, a key piece of the necessary application logic are the programs that define how data storage, processing, training, replication, orchestration, synchronization, and consistency are managed, monitored, and optimized across the tiers in a distributed, hybridized multi-cloud environment.
Hybrid runtimes
Hybridizing runtime environments is the role that integration and middleware fabrics play in the development, deployment, and management of complex, cross-platform applications. Runtimes are whatever containers, virtual machines, orchestration platforms, or other environments execute application logic at any stage of development, testing, or deployment. For example, Docker and Kubernetes have become very popular runtimes for cloud-native microservices, and serverless environments—such as AWS Lambda and Microsoft Azure functions—are emerging runtimes for applications built through functional programming. Increasingly, machine learning models execute in myriad runtimes distributed across hybrid clouds in streaming architectures. To the extent that disparate environments implement lingua-franca APIs, protocols, event models, and other programmatic interfaces, the hybridization of runtimes can be transparent to developers, who, as a consequence, may not need to write code to handle any conversions, translations, or adaptions needed to run their code on or otherwise interface to heterogeneous runtime environments.
Hybrid workloads
Hybridizing workloads involves distributing data, containers, and processing across the hybrid cloud. Typically, this is accomplished through a combination of stream processing, file management systems, database replication, and distributed database updates. Enabling the processing of hybrid workloads is polyglot storage as a global shared repository across all tiers of the hybrid cloud. Another key enabler for hybrid workloads is support for standard APIs for geographically distributed global interoperability across the multicloud. Cloud-native management capabilities that extend existing on-premises data management is a must for robust workflow management across the hybrid cloud.
Compose the end-to-end application in an implementation-agnostic solution pattern
Developers frequently compose solutions as patterns that blend disparate principles, languages, tools, platforms, and other approaches.
Any solution pattern may be hybridized. Developers may express hybridization as whatever pattern is best suited to the solution at hand. These patterns may be expressed in such architectural principles as stateful vs. stateless, procedural vs. declarative, functional vs. imperative, tightly vs. loosely coupled, guaranteed vs. eventually consistent, virtualized vs. bare metal, and so on. Alternately, developers may implement hybrid solutions as higher-level abstractions that execute across hybrid cloud architectures.
Examples such higher-level solution patterns include serverless, cloud-native, virtualization, federation, orchestration, automation, augmentation, and actuation. For example, one might hybridize two or more public serverless offerings within a single application. Likewise, it is even possible to have even more complex hybrids that encompass public serverless environments and various premises-based serverless environments. Consequently, hybrid development strategies for serverless environments might take any of the following forms, which are illustrated in Figure 4:
- Multi-public functional code deployment: A developer might write a functional local app that directly invokes the APIs of stateless, event-driven code that executes in two or more serverless public clouds. For example, a mobile app might consume file-transfer-triggered event notifications from IBM Bluemix OpenWhisk, batch data processing that’s executed in AWS Lambda, and real-time stream processing streams sourced from Microsoft Azure Functions.
- Multi-public functional cross-invocation: A developer might deploy functional microservices code into two or more serverless public clouds. Each of those microservices might invoke stateless, event-driven functions in the other public serverless environments via the APIs that each exposes.
- Hybrid public/private functional deployment and/or cross-invocation: A developer might even deploy functional microservices into private serverless infrastructures as well as one or more public serverless clouds, with API-based cross-invocation among those environments.
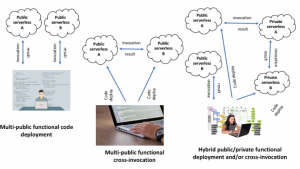
Figure 4: Hybrid Serverless Cloud Architectures
Depending on their programming, application, and IT infrastructure, developers may be able to bridge disparate serverless environments—public and private–via API calls, API gateways, message-oriented middleware, or shared mutable databases.
Action Item
Hybridization is the messy reality of modern development initiatives. In a truly hybridization-friendly application architecture, developers should leverage high-level solution patterns to blend whatever mix of platforms, middleware, and other capabilities address business requirements over the preferred multi-cloud configuration. In pursuing this approach, developers should gravitate toward application platforms–such as those from IBM, Microsoft, Oracle, SAP, VMWare, Cloudera, MapR, and Hortonworks—that are geared for hybrid multi-cloud deployment. A key evaluation criterion should be the extent to which vendors offer premises-based and public-cloud versions of the underlying data, modeling, and other key application capabilities. Another key criterion is the extent to which they also offer high-level development abstractions—such as serverless programming and virtualized resource management—needed to bind hybrid cloud platforms into unified application architectures.


